





Wysoka dostępność serwisu to określenie, które powinno być bardzo dobrze znane wszystkim twórcom biznesów internetowych. To od tego zależy często powodzenie sklepu lub serwisu internetowego. W niniejszym wpisie pokażemy Wam, jak oszacować dostępność serwisu na podstawie deklaracji dostawców infrastruktury, jak tę dostępność podnosić i ile to kosztuje w porównaniu do „liczenia na szczęście”.
W internecie działa i sprzedaje się już niemal wszystko. Sklep funkcjonujący w normalnej rzeczywistości musi się mierzyć z różnego rodzaju ryzykami, którym czasem może, a czasem nie może przeciwdziałać. Musi je jednak znać i wiedzieć, jak zachować ciągłość działania, kiedy coś się wydarzy. W najgorszym wypadku po prostu chodzi o świadomość konsekwencji i akceptację ryzyka, którego usunięcie przekracza sens biznesowy, patrząc z ekonomicznej perspektywy. Dbamy więc o zasilanie awaryjne, wykrywanie zalania, ochronę przed włamaniem, możemy mieć kilka kas, czy nawet dwa łącza na potrzeby autoryzacji kart. Jednakże kiedy droga krajowa, przy której stała restauracja, zostaje zastąpiona autostradą, z której nie ma obok nas zjazdu, to raczej zostaje nam przeniesienie biznesu w inne miejsce. Autostrady nikt nie wybuduje w miesiąc, taki biznes ma wiele lat na decyzje i ew. migrację (taką niekoniecznie wirtualną). W Internecie jest pozornie łatwiej. Przywiązanie do miejsca nie istnieje, ryzyka są łatwiejsze do oszacowania, a przeciwdziałanie jest znacznie mniej kosztowne. Dlaczego pozornie łatwiej? Bo o ile w tradycyjnym biznesie rozsądna osoba sama potrafi ustalić większość oczywistych ryzyk, to w sieci sprowadza się to zwykle do analizy – „a co jak nam serwer padnie?”. Kryje się za tym ogromna ilość potencjalnych problemów i awarii. Z doświadczenia biznesowego wiemy, że w zdecydowanej większości przypadków mamy do czynienia z podejściem „jakoś to będzie” lub liczeniem na szczęście. Liczymy koszt usługi, nie zastanawiając się nad jej realną dostępnością. Dodajmy, że nawet kilkuletnia bezawaryjność niczego nie gwarantuje, bo zwyczajnie usypia czujność.
Wysoka dostępność serwisu. SLA
Analiza tematu dostępności powinna się prawidłowo rozpocząć od oceny ryzyka i ustalenia, ile nasza usługa może nie działać, aby nam to nie zagroziło. I to nawet w najgorszym wariancie, czyli w kluczowym momencie. Do takiego wymagania należy dopasować rozwiązanie, ustalając matematycznie z danych o SLA, czy mamy prawo dochować naszego oczekiwania, wybrać dostawcę infrastruktury, jak i firmę, która zadba o infrastrukturę i będzie nią zarządzać również z odpowiednimi czasami reakcji. Wszystko to powinno być poparte umową SLA z odpowiednimi liczbami, czasami reakcji, a czasem nawet z gwarancjami usunięcia usterki. Wymuszając na dostawcy wysoką jakość, pamiętajmy że nie ma nic za darmo – nikt wysokiego SLA nie wyczaruje, wymaga to odpowiedniej infrastruktury, ludzi, dyżurów, szkoleń i świadomości. To musi kosztować. Przejście ze współdzielonego hostingu na SLA, bez gwarancji czegokolwiek, liczone w małych godzinach może kosztować kilkadziesiąt razy więcej niż ten zwykły hosting. Możemy też kilkadziesiąt razy zmniejszyć potencjalną niedostępność. Analizę biznesową opłacalności musisz przeprowadzić już samodzielnie. W szpitalu nikt nie pyta, czy warto kupić agregat prądotwórczy za 2 mln złotych, bo chodzi o ludzkie życie. Być może sklep z bielizną przetrwa niedziałanie przez 6h? Może jednak koszt utraconego wizerunku będzie zbyt duży?
W kontekście dostępności często pojawia się stwierdzenie SLA (Service Level Agreement), czyli gwarancja dostępności usługi – zwykle podawana w %. Dostawca w ramach swojej oferty mówi nam, że SLA np. jego dzierżawionego nam serwera wynosi 99%. Dużo? To oznacza ponad 7h niedostępności usługi. I to 7h może się zdarzyć o 8.00 rano w dniu wielkiej promocji i potrwać do 15.00. Niezwykle ważne jest ustalenie, co wspomniane SLA oznacza – zwykle będzie to przywrócenie serwera lub np. uruchomienie nowego obok do dyspozycji. Dochodzi więc cała instalacja i odtworzenie z backupu. W skrajnym przypadku mogą to być dni, ale przyjmijmy, że „tylko” podwoimy ten czas realnie. Czy to jest realne? Oczywiście, mając pod opieką setki infrastruktur w wielu lokalizacjach mamy do czynienia z takimi sytuacjami często. Awaria w OVH na przełomie roku 2017/2018 sprawiła, że wiele z tych infrastruktur nie było dostępne kilka godzin, ale… no właśnie, jako że z braku zasilania nastąpił restart części serwerów, to dwie infrastruktury odzyskały 100% działania: jedna po 24h, a druga po 3 dniach!
Dodajmy, że to nie jest niczyja wina. Dostawca dostarcza usługę o określonych parametrach za określoną cenę. Aby zagwarantować ten poziom ponosi określone nakłady, które muszą mu się zwracać. Obiecać można wszystko, ale żeby parametru dotrzymać zawsze i w każdych warunkach to już wymaga nakładów. Dodatkowo, dla pojedynczego serwera zwyczajnie nie da się dochować wyższych parametrów niż obiecane. Albo jest to kosztowne. Przyjmując dzierżawę serwera z kolokacją, łączami za 500 zł miesięcznie – koszt jego zakupu to 10 tys. zł. Są rozwiązania mniej awaryjne, z wykrywaniem awarii, z podmianą podzespołów w czasie pracy – ale jeśli taki serwer kosztuje 100 tys., to zapłacisz za „niby to samo” 5000 zł miesięcznie? Jeśli tak, to ze świadomością za co.
Dlatego zawsze czytaj o SLA i odpowiednio je zintepretuj, a porównując oferty, zastanów się czy obiecywane parametry są realne i jaka za nie jest kara. Bo jeśli za przekroczenie SLA o 1% (kolejne ponad 7h) mamy 10% ceny serwera rekompensaty, no to zwyczajnie jest to obietnica dostawcy, który szacując swoje ryzyko podał nierealny parametr, licząc na szczęście. Bo ewentualna kara jest niewielka, a wystąpi o nią jeszcze mniej klientów. To wynika z ceny usługi oczywiście, bo w niej jest zawarta kalkulacja takiego ryzyka.
Ważna informacja – SLA podaje się w jednostce czasu, np. miesięczne SLA (zazwyczaj) – ma to kluczowe znaczenie na realny czas niedziałania w danym okresie. Im dłuższy okres podania SLA, tym łatwiej go dotrzymać. Bo o ile dostawca przekroczy miesięczne SLA 99%, robiąc jedną przerwę 10h w miesiącu, to już nie przekroczy go, jeśli to samo SLA poda rocznie albo kwartalnie.
Poniżej tabelka uświadamiająca, ile niedziałania w jednostce czasu oznacza dane SLA.
| SLA Dostępność % |
Niedostępność miesieczna |
Niedostępność tygodniowa |
Niedostępność roczna |
|---|---|---|---|
| 90% | 72h | 16.8 godzin | 36 dni |
| 95% | 36h | 8.4 godzin | 18 dni |
| 97% | 21h 36min | 5.04 godzin | 10 dni 19h |
| 98% | 14h 24min | 3.36 godzin | 14 dni 10h |
| 99% | 7h 12min | 1.68 godzin | 3 dni 14h |
| 99.5% | 3h 36min | 50.4 minut | 43h |
| 99.8% | 86min | 20.16 minut | 17h |
| 99.9% | 44min | 10.1 minut | 8h 40min |
| 99.95% | 21min 30s | 5.04 minut | 4h 20min |
| 99.99% | 4min 23s | 1.01 minut | 52min |
Najpopularniejsze jest podawanie SLA w skali miesięcznej. Przestrzegamy przed SLA rocznym – zauważcie, że bardzo wysokie SLA 99,95% podane miesięcznie, z 21 minut zmieni się w ponad 4h w skali roku – czyli jedna awaria w roku trwająca 4h, a SLA ze strony dostawcy będzie dochowane!
Obliczamy realne SLA dla infrastruktury opartej o serwery dedykowane wynajęte w OVH
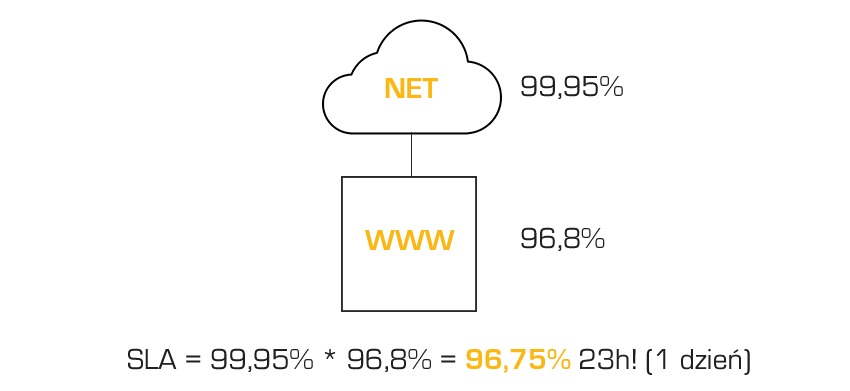
Zgodnie z dokumentami na stronie OVH, zapewniają oni dla dostępu sieciowego SLA 99,95%, a dla pojedynczego serwera SLA wynosi 97,5%. Przy czym dla jasności – SLA liczy się do momentu podstawienia sprawnego serwera. Jeśli mieliśmy pecha i cały poszedł do wymiany, to czeka nas jeszcze postawienie całego systemu z odtworzeniem całości z backupu. Przyjmijmy dla uproszczenia, że mamy raptem do 100 GB danych, backup jest bardzo blisko i szybkodostępny, nad całością pieczę sprawują Hostersi, a klient ma u pakiet opieki administracyjnej z jednym z krótszych czasów reakcji. Dokładamy więc tylko 5h do tego odtworzenia/odzyskania. Czyli dla pojedynczego serwera mamy SLA na poziomie 96,8%. Niestety, przy szeregowym ułożeniu elementów – sieci i dostęp z SLA 99,95 i za nią serwer z SLA 96,8%. Matematyka brutalnie pogarsza nasze wyliczenia, gdyż awaria jednego elementu może wystąpić zaraz za awarią drugiego elementu i czas awarii się nam niejako sumuje. Przy takim połączeniu szeregowym mnożymy po prostu SLA poszczególnych elementów: 99,95 * 96,8% = 96,75% czyli 23 godziny i 24 minuty niedostępności usługi! No to już nie wygląda dobrze. Masz jeden serwer w OVH (lub gdzieś indziej)? Musisz się liczyć z takim potencjalnymi niedostępnościami. Twój biznes musi udźwignąć taki czas niedziałania – technicznie i wizerunkowo.
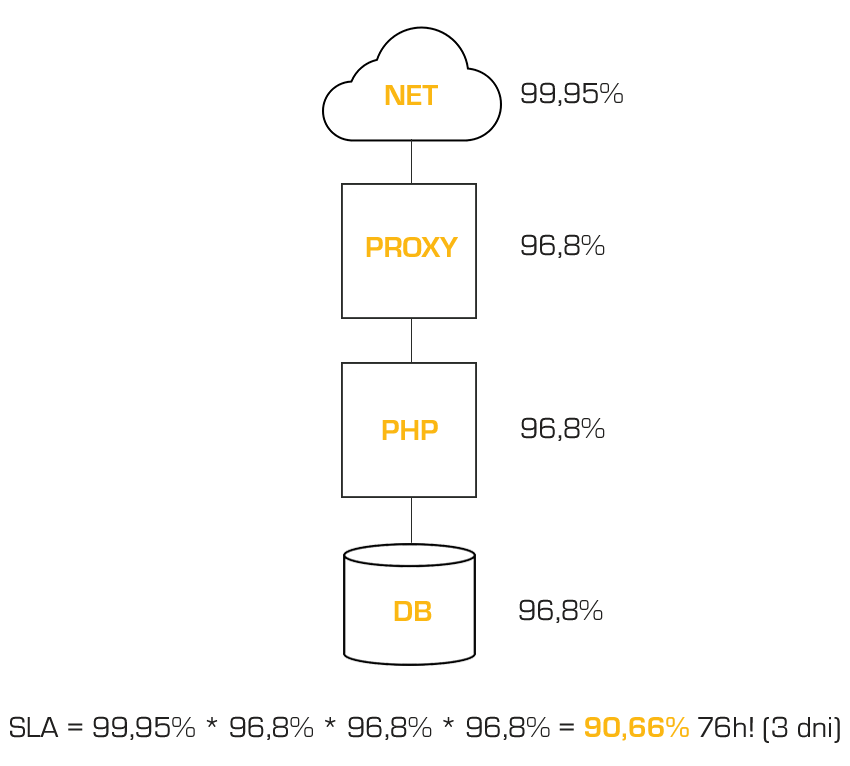
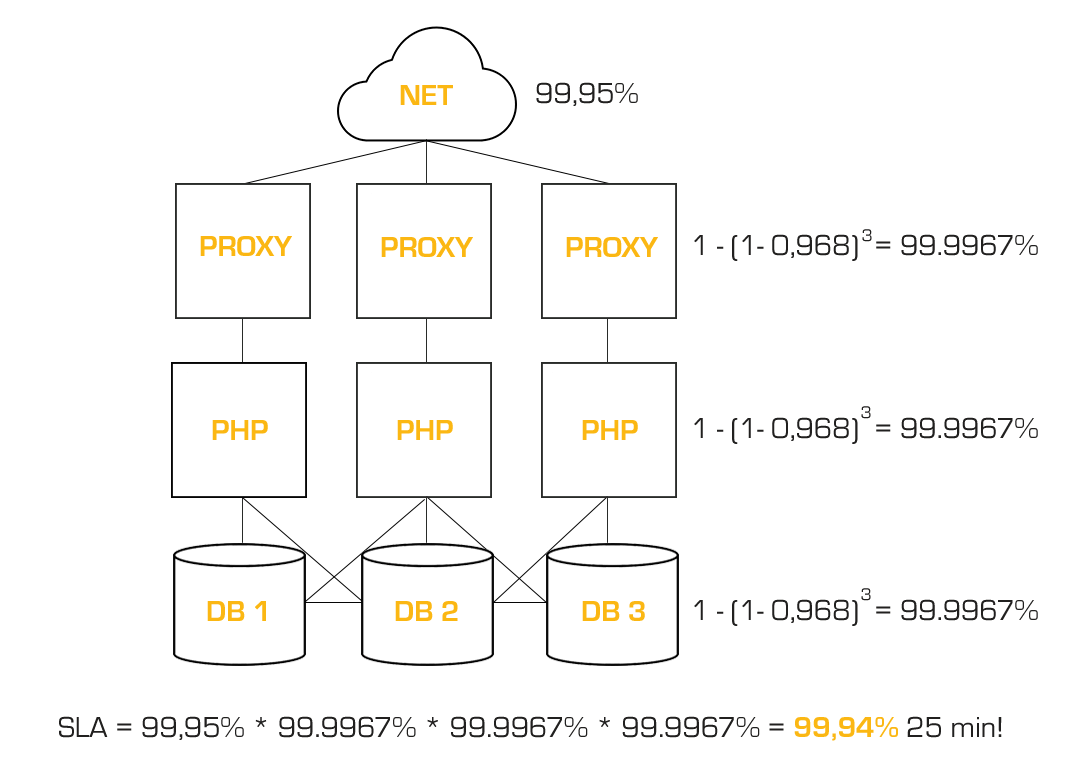
Sytuacja pogarsza się, jeśli używamy kilku serwerów. Przyjmijmy też dość typową sytuację, kiedy mamy 3 serwery – na froncie stoi serwer pełniący rolę proxy i cachujący treści statyczne, za nim jest serwer aplikacyjny (np. serwuje kod sklepu napisanego w PHP), a za tym jest serwer bazy danych. Tym razem matematyka będzie jeszcze bardziej brutalna. Mamy więc 0,9995 (sieć) * 0,968 (serwer proxy) * 0,968 (serwer PHP) * 0,968 (serwer DB) = 0,9066 czyli SLA 90,66% – rzut oka na tabelkę u góry i estymujemy 76 godzin potencjalnej przerwy. To ponad 3 dni!
Katastrofa. Co robić? Jak żyć? OVH złe? Nie, skądże. Usługa ma realne SLA, da się kupić lepszą, ale drożej, albo dużo drożej i nawet jak parametry poprawimy 2x, to nadal będzie 1,5 doby przerwy. Jakim więc cudem te serwisy jeszcze działają? To się nie psuje, czy co? Psuje, ale tutaj na ratunek przychodzi nam redundancja – tworzenie infrastruktury wysokiej dostępności poprzez dublowanie (lub zwielokratnianie) wybranych czy wszystkich komponentów. Można też liczyć na szczęście (w końcu to jest prawdopodobieństwo), ale z nim jest tak, że jednemu serwer nie „padnie” przez 5 lat, a drugiemu 3 razy w jednym miesiącu. A prawdopobieństwo – jak grawitacja – bywa okrutne.
Zaczynamy budowę od dołu, bo brak bazy w niektórych serwisach da się łatwo zamaskować i sprawić, że serwis jednak będzie działał i informował odbiorców, co się stało i kiedy wróci do działania. Dublujemy więc tylko DB na razie. Żeby zrozumieć wpływ takiej duplikacji, zobaczcie co się stanie z SLA. Przy równoległym połączeniu elementów, których jeden może zastąpić od ręki drugi – 1-(1 SLA)^ilość_równoległych_elementów. Czyli 1-(1-0,968)^2 = 99,9%.
No, to się podziało. Z dwóch komponentów z których każdy może nie działać niemal 24h robi nam się układ, z którego wynika, że mamy do czynienia z przerwą na poziomie 4,5 minuty. Przestrzegamy jednak, że cały czas mówimy o prawdopodobieństwie. Jednemu przez 5 lat nie „padnie” jeden serwer, drugiemu w takim układzie wysokiej dostępności „padną” oba…
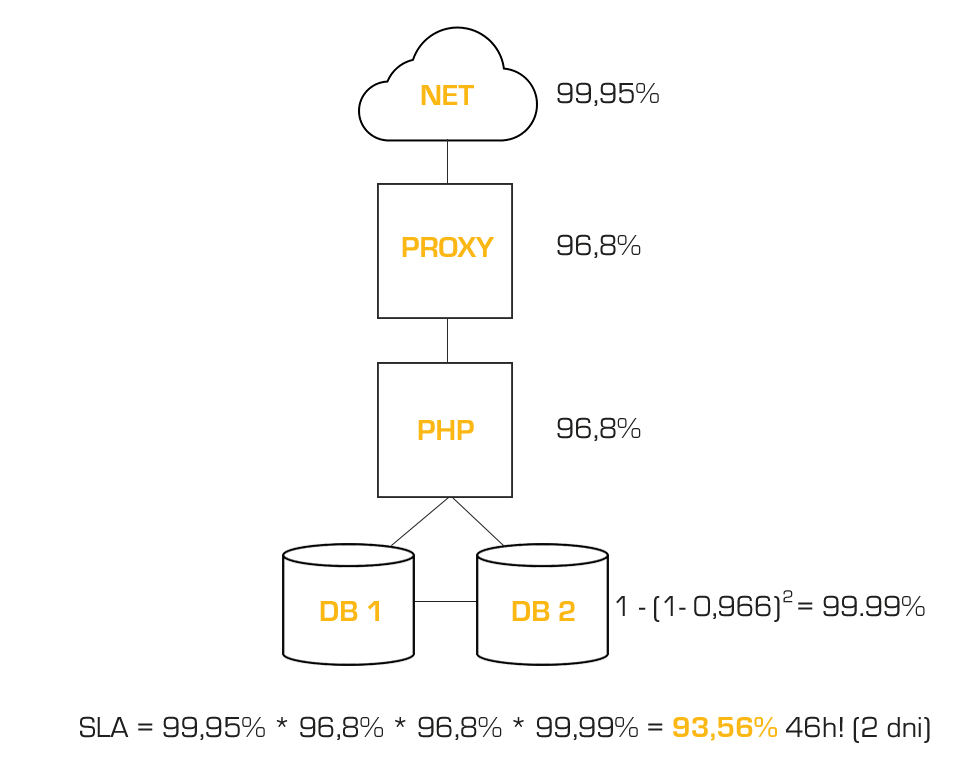
Żeby mieć jeszcze pełniejszy obraz, ustalmy od razu, co się stanie, jeśli serwery będą 3. Mamy poziom 99,997, czyli 1 minuta i 40 sekund. SLA super, a czy warte swojej ceny to już osobna analiza. Mam więc 0,9995 (sieć) * 0,968 (serwer proxy) * 0,968 (serwer PHP) * 1-(1-0,968)^2 (2xserwer DB) = 93,56%. Wprowadzając redundancję na jednym z 3 poziomów schodzimy do 46h – z 3 dni z hakiem do 2 dni z hakiem. Słabo, ale lepiej.
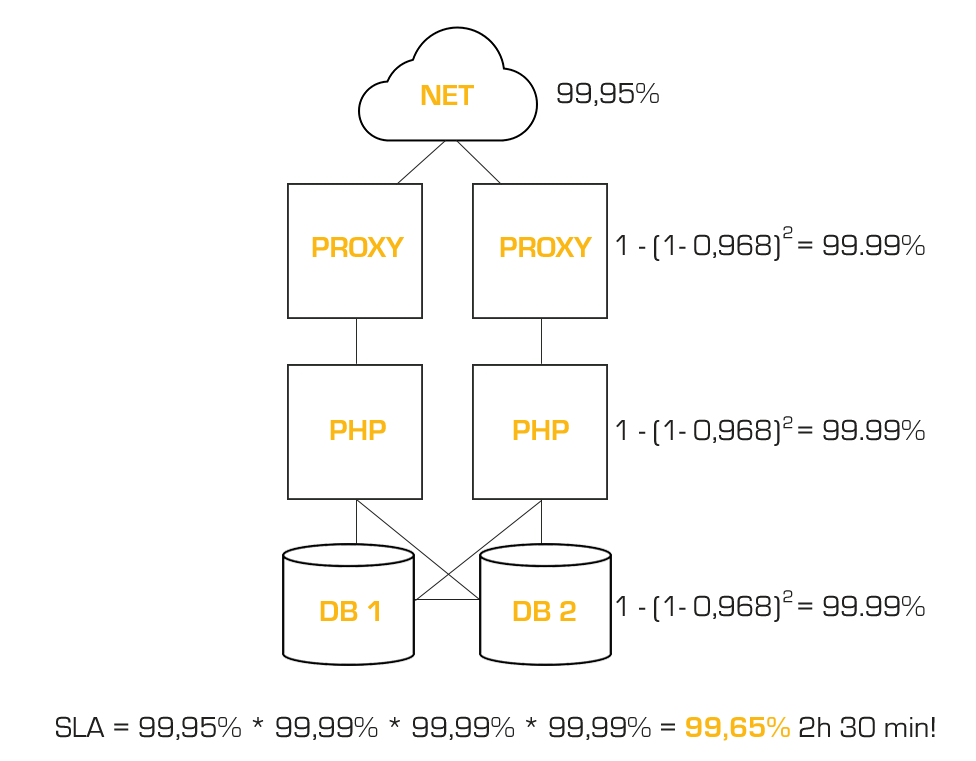
Co się stanie jeśli wprowadzimy redundancję na każdym poziomie?
0,9995 (sieć) * 1-(1-0,968)^2 (2xserwer proxy – LB) * 1-(1-0,968)^2 (2xserwer PHP)* 1-(1-0,968)^2 (2xserwer DB) = 99,65%!
2h 30minut brzmi lepiej niż 76h, wróciliśmy z dalekiej podróży, uff. Od 90,66% do 99,65%. Jakim kosztem? Też policzymy. Nagle się okazuje, że super wyglądające SLA dla sieci 99,95%, teraz stało się najsłabszym punktem. Dla naszej świadomości, jak to wpłynie na SLA, potrajamy wszystkie elementy. Na końcu mamy 99,94% – 25 minut przerwy. No to już wytrzymalibyśmy prawda?
Wyliczenia te mogą być obarczone pewnym błędem. Mamy za mało wiedzy o infrastrukturze dostawcy. Dużo mniej nam da duplikowanie serwerów, jeśli one będą w szafie jeden nad drugim na jednym zasilaniu i jednym switchu. Aby wyliczenia były w pełni realne, musimy mieć pewność separacji sprzętu – awaria jednej grupy nie wpłynie na drugi. Tacy dostawcy, jak OVH, dają nam taką szansę, tak samo np. Oktawave, czy inni. Nie zawsze jest to proste, czasem wymaga naszej uwagi i solidnego dopytania dostawcy. Pozostaje też do rozwiązania wiele software’owych tematów, jak to poskładać, aby działało samodzielnie z HA – tutaj Hostersi zapewniają, że się da (choć łatwiej to zrobić w chmurze). Sprawa znacznie się ułatwia, jeśli skierujemy się w stronę usługi chmurowej AWS, gdzie tego typu wybór i redundancja są w standardzie. Wybierając położenie usług wzajemnie do siebie redundantnych, jest możliwe i gwarantowane.
Niejako efektem ubocznym wprowadzenia redundancji w celu poprawny SLA będzie równoważenie obciążenia oraz zwiększenie możliwości obciążenia (wydajności) całej infrastruktury. Obsłużymy większy ruch lub całość będzie działać szybciej, zwiększymy możliwość obsługi żądań do usługi. Dlatego rozważając sens ekonomiczny takiej zmiany i wprowadzenia redundancji nie można tego pominąć – nie płacisz tylko za SLA, ale również za istotne zwiększenie wydajności – póki nie skorzystamy z redundancji (a to raczej będzie niezmiernie rzadko), mamy dodatkową wydajność – czas ładowania usługi jest kluczowy dla użytkownika i SEO.
Policzmy koszty. Przyjmujemy serwery z dyskami SSD i vRackiem 1GBit – 505zł za serwer.
| Wersja | V1 | V2 | V3 |
|---|---|---|---|
| Opis infrastruktury | 1xProxy/LB 1xPHP 1xDB |
2xProxy/LB 2xPHP 2xDB |
3xProxy/LB 3xPHP 3xDB |
| Koszt infrastruktury | 1515 PLN/mc | 3030 PLN/mc | 4545 PLN/mc |
| SLA | 90,66% | 99,65% | 99,94% |
| Czas niedziałania | 76h | 2h 30min | 25min |
| Koszt poprawy o każdą godzinę | - | 20 PLN (z V1) | 40 PLN (z V1) 760 PLN (z V2) |
Jak widać, pierwszy krok wykonać najłatwiej, koszt poprawy SLA o każdą 1h jest symboliczny, jednak kiedy mamy już niezłe SLA na poziomie 2,5h, koszt poprawy o każdą kolejną godzinę jest prawie 40x wyższy. Dlatego mówi się, że każda kolejna 9-tka w SLA po przecinku to koszt x10. Nie podajemy już tego wyliczenia, ale gdybyśmy na każdym poziomie dodali po 4 serwery, to dojdziemy do SLA 99,95%, czyli nieprzekraczalnego tu SLA sieci, zyskamy tylko 3minuty za 1515 zł, co daje absurdalny koszt ponad 30 tys. zł za propocjonalną godzinę poprawki. Wynika to jednak z wtedy już niskiego SLA sieci. Gdyby ono było na poziomie 99,99%, to na końcu dostajemy 99,989%, 4min 30s – poprawka o 20 minut, co daje już koszt poprawy o teoretyczną godzinę na poziomie 4500 zł. Przy 30 tys. jak za darmo. Cały czas pamiętamy, że są to teoretyczne wyliczenia bez znajomości każdego słabego punktu dostawcy infrastruktury serwerowej.
Jak to będzie wyglądać dla chmury AWS?
Na początek podsumowanie SLA deklarowanego przez Amazon Web Services.
| Usługa AWS | SLA | Kiedy rekompensata | Jaka rekompensata | Link do warunków SLA |
|---|---|---|---|---|
| RDS | 99.95% | Mniejsze niż 99.95% ale większe lub równe 99.0% | 10% | https://aws.amazon.com/rds/sla/ |
| RDS | 99.95% | Mniejsze niż 99.0% | 25% | https://aws.amazon.com/rds/sla/ |
| S3 | 99.9% | Większe lub równe 99.0% ale mniejsze niż 99.9% | 10% | https://aws.amazon.com/s3/sla/ |
| S3 | 99.9% | Mniejsze niż 99.0% | 25% | https://aws.amazon.com/s3/sla/ |
| EC2 | 99.99% | Mniejsze niż 99.99% ale większe lub równe 99.0% | 10% | https://aws.amazon.com/compute/sla/ |
| EC2 | 99.99% | Mniejsze niż 99.0% | 30% | https://aws.amazon.com/compute/sla/ |
| Route 53 | 100% | 5 – 30 minut w okresie rozliczeniowym | Darmowy 1 dzieñ | https://aws.amazon.com/route53/sla/ |
| Route 53 | 100% | 31 minut – 4 godziny w okresie rozliczeniowym | Darmowe 7 dni | https://aws.amazon.com/route53/sla/ |
| Route 53 | 100% | Więcej niż 4 godziny w okresie rozliczeniowym | Darmowe 30 dni | https://aws.amazon.com/route53/sla/ |
Powyżej wartość rekompensaty odnosi się do danej usługi, nie całego rachunku w AWS. Od razu musimy zdać sobie sprawę z kluczowej informacji – dla niektórych usług to jest SLA określające, że dana usługa jest dostępna do zarządzania i da się ją wykreować z panelu, czy API AWS-a, np. jest tak dla EC2 (jest to więc zbieżne z SLA serwera dedykowanego – w zadanym czasie dostajemy czysty serwer do swojej dyspozycji – tutaj możliwość uruchomienia usługi z panelu – identyczne SLA jak dla serwera). Czyli mając instancję EC2 mamy SLA 99,99% dotyczące tego, że zawsze jakaś instancja EC2 będzie dostępna do utworzenia dla nas. AWS gwarantuje, że jak Twoja instancja zniknie, to mając jej obraz, możesz albo szybko utworzyć nową albo, jeśli używasz wolumenów EBS, to najpewniej nie stracisz nawet jednego bajtu danych w razie zniknięcia pojedynczej instancji EC2. AWS jako jeden z nielicznych już dawno postawił sprawę jasno, mówiąc to, co inni niedopowiadali, a co nie było niczym złym de facto (było oczywiste dla osób rozumiejących, jak to działa). Wystarczyło rozumieć, czym jest SLA dowolnego dostawcy – zapewnia infrastrukturę, a nie fakt, że przywróci Twój system do jakiegokolwiek stanu _Z_DANYMI. Taką instancję musimy więc traktować jak pojedynczy serwer, czy VPS, tak samo RDS i podobne usługi. Szereg usług posiada wbudowane SLA, gwarantujące dostępność, dla których o redundancję nie musimy się martwić – aby działała nie musi interweniować człowiek – o awarii możemy się nie dowiedzieć w ogóle. Taki Route53, S3, ELB/ALB czy CloudFront mają z automatu zapewnioną wysoką dostępność i podane SLA dotyczy działania całej usługi. Czyli dla tych usług podane SLA to SLA uwzględniające już wszystkie nieszczęścia i czynności – nie doliczamy żadnego czasu na odtworzenie usługi przez ludzi, odtworzenie danych z kopii. Jednak taki RDS, czy Elasticache wymagają stworzenia clustra wysokiej dostępności, aby uzyskać rzeczywiste HA – z wykorzystaniem multiAZ czyli usługi są replikowane w drugiej strefie dostępności danego regionu (fizycznie niezależna infrastruktura). Dopiero wtedy SLA wyniesie 99,95% dla całej usługi RDS – bez tego zawsze dojdzie interwencja Administratora i odtwarzanie danych (godziny, może i dni). SLA dla EC2 wymaga już doliczenia czasu na odtworzenie środowiska.
Mimo, że może to brzmieć skomplikowanie, dalece upraszcza pracę przy opracowania dobrego HA, o pracy konfiguracyjnej nie wspominając. Kluczowe usługi są z założenia wysokodostępne i wysokobezpieczne w zakresie potencjalnej utraty danych. Dlatego SLA (dostępność usługi) dla S3 wynosi 99,9% ale już pewność, że nasze dane nie ulegną uszkodzeniu to 99 i dziewięć dziewiątek po przecinku. To jednak dwa różne tematy.
Starając się porównać te oba podejścia, czyli składanie infrastruktury z serwerów i budowanie ich w ramach AWS, podajemy wyliczenia w poszczególnych przykładach dla AWS. Siecią się nie zajmujemy, ani DNSami, bo nie było ich wyżej. Dla serwerów przyjęliśmy 5h na instalację i odtworzenie środowiska tutaj, zakładając dobrą opiekę administracyjną i możliwości jakie daje chmura, czas ten skrócimy do 2h. A to dlatego, że – po pierwsze – odbudowa instancji EC2 ze snapshotu to minuty (przy dużych wolumenach może to być naście minut i więcej), a nie instalacja serwera od zera i kopiowanie danych. Zakładając jednak jakiś czas reakcji człowieka i posiadany poziom wsparcia w firmie, która zarządza serwerami, to będzie realny czas, który o wiele łatwiej dochować niż wspomniane 5h.
Czyli dla pojedynczej instancji mamy SLA 99,99% i 2h założone na podstawienie w razie jej zniknięcia. Czyli mamy 99,7% SLA, a dla serwera dedykowanego było to 96,75% – 2h a nie 23h. Nie wdając się na razie w porównanie kosztów, bo oczywiście ogromne zasoby serwera dedykowanego w OVH (z których większość nie skorzysta) wypadną znakomicie w zestawieniu z podobnymi cenowo zasobami AWS (tradycyjny serwer będzie o wiele tańszy przy takim porównaniu). Pytanie tylko, czego potrzebujemy.
Idąc dalej, czyli łańcuszek cache-serwer_aplikacyjny-baza danych. Cache to usługa AWS (CloudFront) z SLA 99,9%, pojedyncza EC2 to nadal 99,99, pojedyncza baza danych RDS to tak samo 99,99 ale i dla EC2 i dla RDS doliczamy nasz czas interwencji odtworzenia środowiska ręcznie (jeśli zniknie RDS musimy odtworzyć usługę z backupu). Obniżmy więc oba SLA do 99,7% czyli do poziomu tych 2h interwencji. 0,999*0,997*0,997 = 99,3% SLA 5h, a nie 72h.
Domyślacie się już pewnie, że dalej będzie postęp jeszcze większy. Jeśli więc zbudujemy redundancję składającą się raptem z dwóch elementów na każdym poziomie to 0,999 (Cache-CloudFront bez zmian) * 1-(1-0,9999)^2 (EC2 w HA – nie ma już odtworzenia bo zrobi się samo, stracimy tylko wydajność na czas awarii, o ile nie wdrożyliśmy autoskalingu) * 0,9995 (SLA dla RDS multiAZ czyli z redundancją) = 99,85% – no to już jakaś 1 godzina. I dalsza poprawa nie jest niemożliwa.
| Serwery dedykowane | AWS | |
|---|---|---|
| Jeden serwer | 96,75% | 99,70% |
| Proxy-PHP-DB | 90,66% | 99,30% |
| HA podwójne wszędzie | 99,65% | 99,85% |
Wygląda to o wiele lepiej od początku, a rozwiązanie pozachmurowe zbliża się dopiero do AWS przy dużym HA. Ma jeszcze jedną przewagę – tutaj mamy przejrzystość w całym zakresie SLA i usług od łącza, przez zasoby, po dane. Wiemy, że jak użyjemy EC2 w drugiej strefie dostępności, to nie ma żadnych punktów wspólnych z pierwszą strefą, żadnych. SLA usług obejmuje sieć, DNSy i dostęp do dysków sieciowych. Wyliczenie jest więc w 100% pewne. Nie trzeba zostawiać niejasnego czynnika jak w serwerach dedykowanych (nikt z masowych dostawców nie ma tutaj przejrzystej polityki – jeśli uważasz inaczej – chętnie wysłuchamy dlaczego).
Dodajmy też, że do wyliczeń przyjęto dane SLA dostępne w grudniu 2018 roku.
Wysoka dostępność serwisu. Jak ją ustalić i wyliczyć? Podsumowanie
Nie chcemy przybierać tonu, że chmura jest lekiem na wszystko, a serwery dedykowane są złe. Tak, w chmurze jest często taniej (patrząc na TCO – prawie zawsze taniej, im większa infrastruktura tym pewniejsze jest, że jest taniej), zawsze elastyczniej, pewniej i łatwiej odbudować cokolwiek się zepsuje. Są jednak zastosowania, gdzie ani to potrzebne nie jest, ani koszt nie będzie do zaakceptowania. Cały wywód dedykujemy tym, którzy mają na sercu realia i liczby, a nie szczęście po stronie rachunku prawdopodobieństwa awarii.
Hostersi zaopiekują się zarówno infrastrukturą, opartą o serwery dedykowane, jak i chmurową. W naszym portfolio nadal lwią część stanowią rozwiązania tradycyjne, ale ich udział systematycznie spada. Dane pokazują, że w Polsce jeszcze mamy bardzo niski poziom użycia rozwiązań chmurowych, więc dużo pracy przed nami.
Dalsza poprawa SLA gdziekolwiek, to już tylko ultra dobrze napisana aplikacja i Disaster Recovery (najlepiej u innego dostawcy).
Tomasz Dwornicki
CEO w Hostersi
Pytania? Skontaktuj się z nami
Zobacz również:
Jak używać pliku stanu zdalnego remotestate w środowisku Terraform?
Rewolucja w bezpiecznych połączeniach VPN z WireGuard
Chmura obliczeniowa nie taka straszna. Wprowadzenie do Amazon Web Services
Tworzenie nowego konta AWS i zasobów przy użyciu opcji multiple provider w środowisku Terraform

