





Jak używać pliku stanu zdalnego remotestate w środowisku Terraform? Zapraszamy do lektury wpisu na naszym blogu, w którym zdradzamy tajniki devopsowej kuchni.
Bezpieczne przechowywanie informacji o stanie
Bez stosownej konfiguracji terraform przechowuje stan zrealizowanej infrastruktury w pliku, który tworzy podczas uruchamiania operacji apply, a mianowicie terraform.tfstate w katalogu głównym projektu.
Lokalny plik nie jest jednak najlepszym pomysłem, zwłaszcza w sytuacji, gdy dokonujemy operacji terraformowych z różnych komputerów czy też z operacji tych chce korzystać każdy członek zespołu wspólnie pracującego nad projektem. Można oczywiście założyć, że zostanie wykorzystany system kontroli wersji, a zmiany zostaną wprowadzone do repozytorium, ale ani nie jest to bezpieczne, ani też nie zapewnia ochrony przed uruchomieniem zmian naraz przez dwie różne osoby, czy też, co gorsza, wykorzystania nieaktualnego pliku stanu.
Najczęściej rozwiązuje się ten problem poprzez używanie tzw. backendu, czyli utrzymywaniu stanu na zdalnym magazynie, do którego dostęp posiadają wszyscy członkowie zespołu, a do którego dostęp podczas korzystania z terraforma jest kontrolowany. W tym artykule pokazano realizację przy użyciu usług Amazon Web Services (Hostersi są resellerem i partnerem AWS o statusie Advanced Consulting Partner), czyli magazynu S3 oraz bazy DynamoDB. Oznacza to, że do przechowywania pliku (lub plików) stanu używany jest bucket w magazynie S3 – co wyeliminuje sytuacje posiadania przez różnych członków zespołu nieaktualnego stanu terraforma. Dostęp do tego stanu kontrolowany jest z kolei przez odpowiedni obiekt (lock) założony w tabeli DynamoDB. Każdorazowa próba operacji na infrastrukturze zarządzanej przez terraform spowoduje „przejęcie” locka, co uniemożliwi innym uruchomienie operacji w tym samym czasie.
DevOps nie byłby DevOpsem, gdyby nie zautomatyzował również operacji zakładania zasobów potrzebnych do powyżej opisanego działania, a zatem:
Automatyzacja założenia magazynu backend
Ponieważ dostawcą usług jest w tym przypadku AWS, uruchamiamy providera z podstawowymi opcjami (profile jest nazwą profilu określoną w credentials konfiguracji aws):

Bucket w S3, w którym umieszczane będą pliki stanu terraforma, powinien spełniać następujące warunki:
• być zaszyfrowany,
• mieć włączone wersjonowanie,
• nie umożliwiać ręcznego usunięcia
Poniższy kod zakłada klucz KMS służπący do szyfrowania oraz sam ący do szyfrowania oraz sam bucket:

W powyższym kodzie nie skorzystano z opcji ustawienia nazwy bucketu, lecz prefiksu (bucket_prefix)– w tym przypadku nazwa zostanie uzupełniona o wygenerowany liczbowy identyfikator, ułatwiający założenie unikatowego bucketu. Jest to polecany sposób z uwagi na fakt, że nazwy w S3 są unikatowe globalnie, w skali całego S3, nie pojedynczego konta. Do konfiguracji dołączono dodatkowo linijkę force_destroy = true – to ułatwienie techniczne, które pozwoli operacji terraform destroy na usunięcie bucketu, jeśli jakieś pliki się w nim znajdują. Na końcu kodu upewniono się, że zostanie wyeksportowana nazwa bucketu.
Tabelę DynamoDB zawierającą lock zakłada się dość podobnie, przy czym:
• nazwa tabeli może być dowolna,
• musi istnieć założony atrybut o nazwie LockID i typie string (terraform będzie się do
niego odwoływał),
• należy ustalić minimalne wartości red_capacity oraz write_capacity.
Zalecenia powyższe zrealizuje się przy użyciu kodu:

Powyższy kod zawiera odwołania do zmiennej deployment_name celem utrzymania konwencji nazewnictwa oraz umożliwienia sytuacji, w której z jednego konta korzysta wiele środowisk (chociaż polecamy zakładanie osobnych kont w takim przypadku!). I podobnie jak poprzednio, upewniamy się, że zostanie wyeksportowana nazwa locka.
Jak używać pliku stanu zdalnego remotestate w środowisku Terraform. Uwagi techniczne
• Backend zakłada się siłą rzeczy początkowo korzystając z lokalnego pliku stanu. Chociaż możliwe jest przeniesienie powyżej realizowanego stanu również na backend, HashiCorp proponuje, aby akurat zakładana podstawowa infrastrkutura dla backendu była po prostu zapisywana w repozytorium pod kontrolą wersji. Ma to związek z faktem, iż bardzo rzadko wystąpi konieczność zmian akurat w tym komponencie infrastruktury (raczej tylko zniszczenie), a separacja od właściwego projektu jest wręcz wskazana.
Konfiguracja backendu w nowym środowisku
Dla środowiska, czy też komponentu, mającego już skorzystać z backendu, konfigurację uzupełniamy o dane zrealizowanej infrastruktury:

Przedstawiony kod wymaga kilku komentarzy:
• Zdefiniowany tutaj parametr key stanowi o kluczu, w którym będą zapisywane pliki stanu (można go uważać za folder w buckecie). To pozwoli na korzystanie z tego samego backendu różnym komponentom infrastruktury.
• Parametr region oznacza region, w którym został założony bucket. Są to obiekty globalne, ale istnieją w odpowiednim regionie.
• Parametry backendu niestety nie mogą być zdefiniowane jako zmienne, ani tym bardziej obliczane na podstawie kilku zmiennych. Wynika to z faktu, iż backend zakładany jest bardzo wcześnie podczas procesu uruchamiania terraforma i niedostępna jest jeszcze interpolacja zmiennych. Jedynym sposobem automatyzacji jest tutaj użycie operacji terraform init z parametrami, które można ustawiać w skrypcie uruchomieniowym, jak w przykładzie poniżej:

Współdzielenie informacji o zasobach pomiędzy oddzielnie uruchamianymi komponentami
Używanie zdalnego backendu pozwala osiągnąć dodatkowe korzyści. Można dzięki temu podzielić realizowaną infrastrukturę na osobne komponenty, z których każdy posiada swój stan w osobnym kluczu, a jednocześnie może korzystać z informacji zawartych w plikach stanu innych komponentów, jesli tylko korzystają z tego samego backendu. Metoda taka nosi nazwę remote_state.
Można sobie zatem wyobrazić, iż definiujemy osobno komponent odpowiedzialny za realizację (i utrzymanie) stanu sieciowej infrastruktury (sieć VPC, podsieci, trasy routingu, gateway, itp.), osobno natomiast komponent odpowiedzialny za konfigurację domeny (czyli w przypadku AWS – Route53), czy też maszyn wirtualnych (analogicznie – EC2).
Strukturą pozwalającą na realizację takiego zadania jest źródło danych (data source) o nazwie terraform_remote_state. Źródło danych nie jest zasobem per se, tzn. jego definicja nie spowoduje utworzenia zasobu, spowoduje natomiast próbę pobrania danych o takowym, jeśli istnieje. Terraform_remote_state, zgodnie z nazwą, pobiera dane z innego pliku stanu terraforma (które zostały zdefiniowane jako outputs).
Najlepiej sytuację ilustruje poniższy (nieco wyidealizowany) przykład:
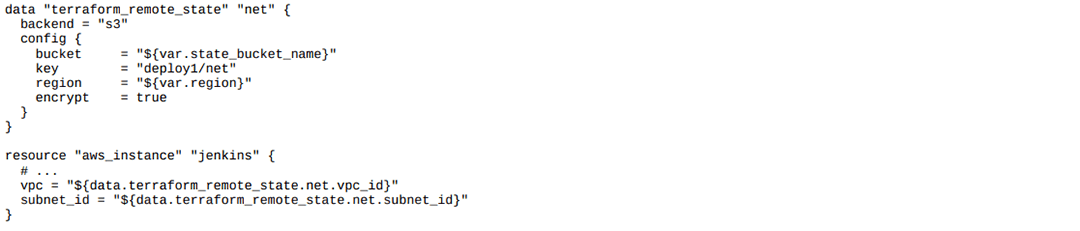
W przedstawionym przykładzie, źródło danych (data) o nazwie net pozwala na pobranie danych z klucza deploy1/net, w którym to środowisku utworzono sieć VPC wraz z podsiecią i przekazano vpc_id oraz subnet_id jako output. Następnie, w obecnym środowisku tworzona jest maszyna EC2 w sieci, której identyfikator pobierany jest właśnie z terraform_remote_state.
Wrap-up, czyli co zrobiliśmy
Z pomocą przedstawionego kodu, można zautomatyzować założenie elementów niezbędnych do funkcjonowania backendu, czyli zdalnego magazynu na pliku stanu infrastruktury zarządzanej przez Terraform. Dzięki temu:
• wszyscy uczestniczący w pracy nad infrastrukturą posiadają aktualny stan terraforma,
• dostęp do tego stanu jest kontrolowany, a każdorazowa próba operacji na infrastrukturze zarządzanej przez terraform spowoduje „przejęcie” locka, co uniemożliwi innym uruchomienie operacji w tym samym czasie,
• można infrastrukturę podzielić na części (komponenty), z których każdy może czerpać informacje o stanie innych komponentów.
Dajcie znać, jakie rozwiązania stosujecie w swoich terraformowanych infrastrukturach! Jak duże macie state file? A może macie kłopoty? Happy terraforming!
Maciej Rostański
Devops Engineer w Hostersi
Pytania? Skontaktuj się z nami
Zobacz również:
Czy warto zatrudniać własnego administratora?
Rewolucja w bezpiecznych połączeniach VPN z WireGuard
Chmura obliczeniowa nie taka straszna. Wprowadzenie do Amazon Web Services

