





AWS Step Functions obsługuje teraz ponad 220 usług i ponad 10 000 akcji AWS API. Umożliwia to bezpośrednie korzystanie z integracji AWS SDK zamiast pisania funkcji AWS Lambda jako proxy.
Jedną z takich integracji usług jest Amazon S3. Obecnie piszesz skrypty za pomocą poleceń AWS CLI S3, aby osiągnąć automatyzację wokół uruchamiania zadań S3. Na przykład S3 integruje się z AWS Transfer Family, tworzy niestandardową kontrolę bezpieczeństwa, podejmuje działania na bucketach S3 w tworzeniu obiektów S3 lub organizuje workflow wokół pobierania obiektów S3 Glacier Deep Archive. Te uruchomienia skryptu nie zapewniają historii wykonywania ani łatwego sposobu weryfikacji zachowania.
Integracja Step Functions AWS SDK z S3 deklaratywnie tworzy bezserwerowe workflow’y wokół zadań S3 bez polegania na tych skryptach. Możesz sprawdzić poprawność historii wykonania i zachowania workflow’u funkcji Step Functions.
Ten post przedstawia jeden z przypadków użycia S3. Pokazuje, jak organizować workflow’y związane z pobieraniem obiektów S3 Glacier Deep Archive, szacowaniem kosztów i interakcją z twórcą żądania za pomocą funkcji Step Functions. Aplikacja demo zawiera dodatkowe szczegóły dotyczące całej architektury.
S3 Glacier Deep Archive to klasa pamięci w S3 używana do rzadko używanych danych. Usługa zapewnia trwałe i bezpieczne długoterminowe przechowywanie, oferując natychmiastowy dostęp dla efektywność kosztowej. Zarchiwizowane obiekty należy przywrócić, zanim będzie można je pobrać. Obsługuje dwie opcje wyszukiwania obiektów:
- Standard – Dostęp do obiektów w ciągu 12h od czasu rozpoczęcia procesu przywracania.
- Bulk – Dostęp do obiektów w ciągu 48h od czasu rozpoczęcia procesu przywracania.
Business use case
Rozważ instytut badawczy, który przechowuje kopie zapasowe w S3 Glacier Deep Archive. Kopie zapasowe są utrzymywane w S3 Glacier Deep Archive w celu zapewnienia redundancji. Instytut ma wielu badaczy z jednym centralnym zespołem IT. Gdy naukowiec żąda obiektu z S3 Glacier Deep Archive, centralny zespół IT pobiera go i obciąża odpowiednią grupę badawczą kosztami wyszukiwania i przesyłania danych.
Badacze są użytkownikami końcowymi i nie działają w chmurze AWS. Lokalnie prowadzą klastry obliczeniowe i polegają na centralnym zespole IT, który dostarczy im przywrócone archiwum. Członek zespołu badawczego wnioskującego o odzyskanie obiektu przekazuje do centralnego zespołu IT następujące informacje:
- Klucz obiektu, który ma zostać odzyskany.
- Liczba dni, przez które badacz potrzebuje obiektu dostępnego do pobrania.
- Adres email badacza.
- Odzysk w ciągu 12 lub 48 godzin SLA. Określa to, czy pobieranie jest odpowiednio w wersji „Standard” lub „Bulk”.
Poniższa ogólna architektura wyjaśnia konfigurację AWS i interakcje między badaczem a architekturą centralnego zespołu IT.
Podgląd architektury

Rysunek 1: Diagram architektury
- Badacz używa aplikacji typu front-end do żądania pobrania obiektu z archiwum S3 Glacier Deep Archive.
- Amazon API Gateway synchronicznie wywołuje AWS Step Functions Express Workflow.
- Step Functions inicjuje RestoreObject z archiwum S3 Glacier Deep Archive.
- Step Functions przechowuje metadane tego odzyskiwania w tabeli Amazon DynamoDB.
- Step Functions używa Amazon SES do wysyłania wiadomości e-mail do badacza o rozpoczęciu odzyskiwania archiwów.
- Po zakończeniu S3 wysyła zdarzenie RestoreComplete do Amazon EventBridge.
- Reguła EventBridge wyzwala kolejne funkcje Step Functions do przetwarzania końcowego po zakończeniu przywracania.
- Funkcja Lambda w funkcji Step Functions oblicza szacunkowy koszt (odzyskiwanie i przesyłanie danych) i aktualizuje istniejące metadane w tabeli DynamoDB.
- Synchronizacja danych z tabeli DynamoDB za pomocą zapytań Amazon Athena Federated Queries w celu generowania dashboardów raportów w Amazon QuickSight.
- Step Functions używa SES do wysyłania wiadomości e-mail do badacza ze szczegółami kosztów.
- Gdy badacz otrzyma wiadomość e-mail, używa aplikacji front-end do wywołania punktu końcowego interfejsu API /download.
- API Gateway wywołuje funkcję Lambda, która generuje wstępnie podpisany adres URL S3 pobranego obiektu i zwraca go w odpowiedzi.
Konfiguracja
- Aby sklonować repozytorium, uruchom:
git clone https://github.com/aws-samples/aws-stepfunctions-examples.git
cd cdk/app-glacier-deep-archive-retrievalBash
- Aby wdrożyć aplikację, uruchom:
cdk deploy –all
Identyfikacja elementów workflowu
Rozpoczęcie workflowu przywracania obiektów
Pierwszym elementem jest zaakceptowanie prośby badacza o rozpoczęcie procesu odzyskiwania archiwum. Przykładowa aplikacja utworzona na podstawie wersji demo to podstawowa aplikacja typu front-end, która pokazuje pliki z bucketu S3, który zawiera obiekty przechowywane w S3 Glacier Deep Archive. Badacz pobiera żądania plików z aplikacji front-end, do której dociera adres URL przykładowej aplikacji Amazon CloudFront.

Rysunek 2: Menu Glacier Deep Archive Retrieval
Aplikacja typu front-end prosi badacza o adres e-mail, liczbę dni, przez które badacz chce, aby obiekt był dostępny do pobrania, oraz szacowany czas na prędkość pobierania. W oparciu o prędkość wyszukiwania, badacz akceptuje zarówno pobieranie typu Standard obiektów, jak i pobieranie typu Bulk. Aby to przetestować, umieszcza obiekty w buckecie danych w klasie pamięci masowej S3 Glacier Deep Archive i używa aplikacji front-end, aby je pobrać.
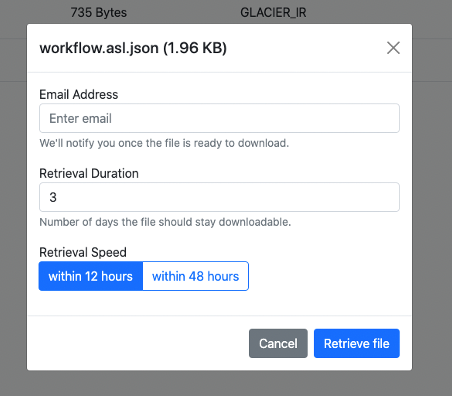
Rysunek 3: Monit o odzyskiwaniu pozycji
Badacz wybiera następnie opcję Retrieve file. Akcja ta wywołuje punkt końcowy interfejsu API dostarczony przez API Gateway. API Gateway synchronicznie wywołuje workflow Step Functions Express. Sprawdza to poprawność żądania przywrócenia obiektu, pobiera metadane obiektu i rozpoczyna przywracanie obiektu z archiwum S3 Glacier Deep Archive.
Automat stanów przechowuje metadane wywołania AWS SDK obiektu przywracania w tabeli DynamoDB do późniejszego wykorzystania. Możesz użyć tych metadanych do zbudowania dashboardu w Amazon QuickSight do celów raportowania i administracji. Wreszcie maszyna stanu używa Amazon SES, aby wysłać wiadomość e-mail do badacza, powiadamiając go o procesie inicjacji przywracania obiektu:
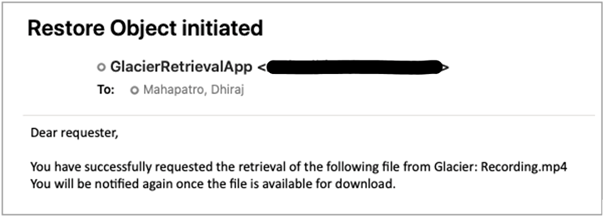
Rysunek 4: Inicjowanie przywracanie obiektu
Poniższa maszyna stanów pokazuje workflow:
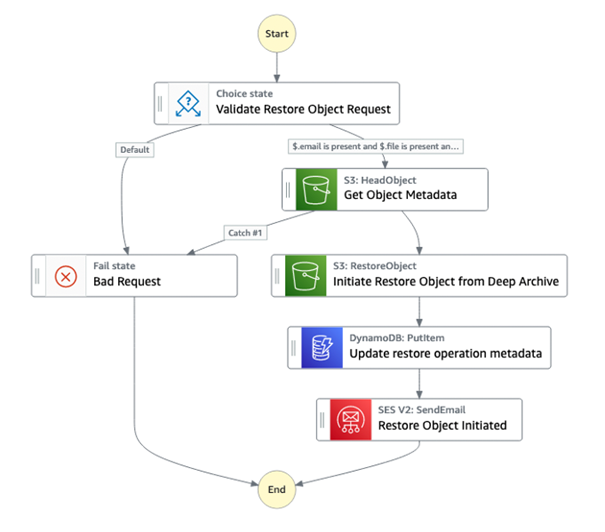
Rysunek 5: Diagram workflow
Możliwość deklaratywnego używania interfejsów API S3 przy użyciu zestawu AWS SDK z funkcji Step Functions ułatwia integrację z S3. Takie podejście pozwala uniknąć pisania funkcji Lambda do opakowywania wywołań SDK. Poniższa część definicji automatu stanów przedstawia użycie interfejsów API S3 HeadObject i RestoreObject:
"Get Object Metadata": {
"Next": "Initiate Restore Object from Deep Archive",
"Catch": [{
"ErrorEquals": ["States.ALL"],
"Next": "Bad Request"
}],
"Type": "Task",
"ResultPath": "$.result.metadata",
"Resource": "arn:aws:states:::aws-sdk:s3:headObject",
"Parameters": {
"Bucket": "glacierretrievalapp-databucket-abc123",
"Key.$": "$.fileKey"
}
},
"Initiate Restore Object from Deep Archive": {
"Next": "Update restore operation metadata",
"Type": "Task",
"ResultPath": null,
"Resource": "arn:aws:states:::aws-sdk:s3:restoreObject",
"Parameters": {
"Bucket": "glacierretrievalapp-databucket-abc123",
"Key.$": "$.fileKey",
"RestoreRequest": {
"Days.$": "$.requestedForDays"
}
}
}
Możesz rozszerzyć poprzedni workflow i zbudować własne worflowy Step Functions, aby zaaranżować inne workflowy związane z S3.
Przetwarzanie po zakończeniu przywracania obiektu
S3 RestoreObject to długotrwały proces dla obiektów S3 Glacier Deep Archive. S3 emituje powiadomienie o zdarzeniu RestoreCompleted po zakończeniu przywracania obiektu do EventBridge.
Skonfigurowano regułę EventBridge, aby wyzwolić inny workflow funkcji Step Functions jako cel dla tego zdarzenia. Ten workflow zajmuje się przetwarzaniem końcowym przywracania obiektów.
cfnDataBucket.addPropertyOverride('NotificationConfiguration.EventBridgeConfiguration.EventBridgeEnabled', true);
Reguła EventBridge wyzwala następujący workflow funkcji Step Functions i przekazuje payload zdarzenia jako dane wejściowe do wykonania funkcji Step Functions:
new aws_events.Rule(this, 'invoke-post-processing-rule', {
eventPattern: {
source: ["aws.s3"],
detailType: [
"Object Restore Completed"
],
detail: {
bucket: {
name: [props.dataBucket.bucketName]
}
}
},
targets: [new aws_events_targets.SfnStateMachine(this.stateMachine, {
input: aws_events.RuleTargetInput.fromObject({
's3Event': aws_events.EventField.fromPath('$')
})
})]
});
Workflow Step Functions pobiera metadane obiektu z tabeli DynamoDB, a następnie wywołuje funkcję Lambda w celu obliczenia szacunkowego kosztu. Funkcja Lambda oblicza szacunkowe koszty odzyskiwania i przesyłania danych za pomocą contentLength pobranego obiektu i cennika Price List API dla kosztu jednostkowego. Następnie workflow aktualizuje obliczony koszt w tabeli DynamoDB.
Koszt pobrania i koszt wysłania danych są proporcjonalne do wielkości pobranego obiektu. Workflow Step Functions również wywołuje funkcję Lambda w celu utworzenia adresu URL pobierania interfejsu API do pobierania obiektów. Na koniec wysyła do badacza e-mail z szacowanym kosztem i adresem URL pobierania jako powiadomieniem o zakończeniu przywracania.
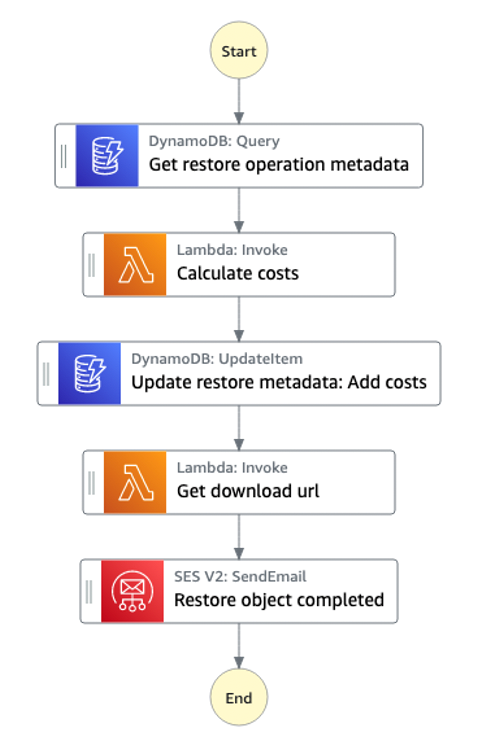
Rysunek 6: Diagram workflow studio
Powiadomienie e-mail do badacza wygląda tak:
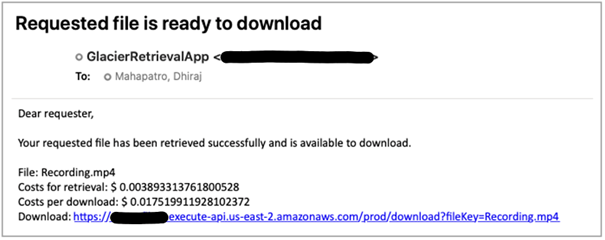
Rysunek 7: Przykładowy email
Pobieranie przywróconego obiektu
Po zakończeniu przywracania obiektu badacz może pobrać obiekt z aplikacji front-end.

Rysunek 8: Menu pobierania front-end
Badacz wybiera akcję Download, która wywołuje inny punkt końcowy API Gateway. Punkt końcowy integruje się z funkcją Lambda jako backend, który tworzy wstępnie podpisany adres URL S3 wysyłany jako odpowiedź do przeglądarki.
Administrowanie przywracaniem obiektów
Architektura ta zapewnia również centralnemu zespołowi IT widok umożliwiający zrozumienie wykorzystania przywracania obiektów. Osiągasz to, tworząc raporty i dashboardy na podstawie metadanych przechowywanych w DynamoDB.
Przykładowa aplikacja korzysta z zapytań Amazon Athena Federated Queries i Amazon Athena DynamoDB Connector do generowania dashboardów raportów w Amazon QuickSight. Możesz także użyć integracji Step Functions AWS SDK z Amazon Athena i wizualizować workflow w konsoli Athena.
Poniższa wizualizacja QuickSight pokazuje liczbę przywróconych obiektów S3 Glacier Deep Archive według ich contentType:
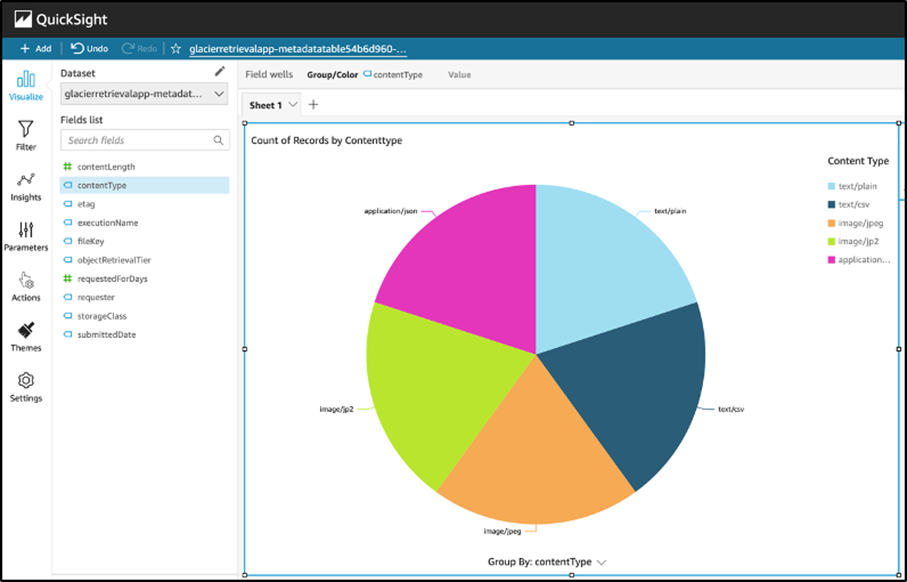
Rysunek 9: Wizualizacja QuickSight
Warto rozważyć
Przy poprzednim podejściu powinieneś wziąć pod uwagę, że:
- Pobieranie obiektów należy rozpocząć w tym samym regionie, co region zarchiwizowanego obiektu.
- S3 Glacier Deep Archive obsługuje tylko pobieranie typu Standard i Bulk.
- Musisz włączyć powiadomienie o zdarzeniu „Object Restore Completed” w buckecie S3 z obiektem S3 Glacier Deep Archive.
- E-mail badacza musi być zweryfikowany w SES.
- Użyj funkcji Lambda dla Cennika GetProducts API, ponieważ punkty końcowe usługi są dostępne w określonych Regionach.
Czyności końcowe
Aby wyczyścić infrastrukturę używaną w tej przykładowej aplikacji, uruchom:
cdk destroy –all
Podsumowanie
Integracja z pakietem AWS SDK Step Functions otwiera różne możliwości organizowania workflows. Step Functions zapewnia natywną obsługę ponownych prób i obsługi błędów, co odciąża ich ciężką obsługę ręcznie w skryptach.
Ten post przedstawia jeden przykładowy przypadek użycia z archiwum S3 Glacier Deep Archive. Dzięki integracji AWS SDK w Step Functions możesz zbudować dowolną aranżację workflowu przy użyciu interfejsów API sterujących S3 lub S3.
Na przykład workflow w celu wymuszenia szyfrowania AWS Key Management Service w oparciu o zdarzenie S3 lub utworzenie statycznej strony internetowej hostowanej na żądanie w kilku krokach.
Dzięki różnym wywołaniom API S3 dostępnym w Step Functions’ Workflow Studio, możesz deklaratywnie zbudować workflow Step Functions, zamiast imperatywnie wywoływać każdy interfejs API S3 ze skryptu powłoki lub wiersza poleceń. Więcej informacji znajdziesz w aplikacji demonstracyjnej.
Aby uzyskać więcej zasobów do nauki o bezserwerowych rozwiązaniach, odwiedź stronę Serverless Land.

