





Od czasu pojawienia się dużych zbiorów danych ponad dekadę temu, Hadoop – platforma open-source, która służy do wydajnego przechowywania i przetwarzania dużych zbiorów danych – odgrywa kluczową rolę w przechowywaniu, analizowaniu i ograniczaniu tych danych w celu zapewnienia wartości dla przedsiębiorstw. Hadoop umożliwia przechowywanie ustrukturyzowanych, częściowo ustrukturyzowanych lub nieustrukturyzowanych danych dowolnego rodzaju w klastrach pamięci masowej w sposób rozproszony przy użyciu rozproszonego systemu plików Hadoop (HDFS), a także równoległe przetwarzanie magazynów danych w HDFS przy użyciu MapReduce. W przypadkach użycia, w których hostujesz klaster Hadoop w AWS, na przykład uruchamiasz Amazon EMR lub klaster Apache HBase, przetwarzanie danych pośrednich w pamięci blokowej jest wymagane w celu uzyskania optymalnej wydajności przy równoczesnym zrównoważeniu kosztów.
W tym artykule autorzy przedstawiają przegląd usługi blokowej pamięci masowej w AWS – Amazon Elastic Block Store (Amazon EBS) i zalecają typ woluminu EBS st1, który najlepiej nadaje się do dużych obciążeń danych. Następnie omawiają zalety woluminów st1 i optymalną konfigurację st1, która maksymalizuje cenę i wydajność systemu plików HDFS. Skonfigurowali środowisko testowe, które porównuje trzy klastry, z których każdy ma inną konfigurację woluminu st1. Wykorzystując metryki Amazon CloudWatch, można monitorować wydajność woluminów st1 podłączonych do tych trzech klastrów, a następnie stwierdzić, który klaster z odpowiednią konfiguracją woluminów zapewnia optymalną wydajność. Dzięki tym obserwacjom można zoptymalizować woluminy st1 przy użyciu zweryfikowanej konfiguracji w celu zrównoważenia wydajności kosztowej dla obciążeń związanych z dużymi zbiorami danych.
Amazon Elastic Block Store
Amazon Elastic Block Store (Amazon EBS) to łatwa w użyciu, skalowalna i wydajna usługa blokowego przechowywania danych zaprojektowana dla Amazon Elastic Cloud Compute (Amazon EC2). Amazon EBS zapewnia wiele typów woluminów, które są obsługiwane przez dyski półprzewodnikowe (SSD) lub dyski twarde (HDD). Te typy woluminów różnią się charakterystyką wydajności i ceną, co pozwala dostosować wydajność pamięci masowej i koszt do potrzeb aplikacji. Woluminy oparte na dyskach SSD (io2 Block Express, io2, io1, gp3 i gp2) są zoptymalizowane pod kątem obciążeń transakcyjnych obejmujących częste operacje odczytu i zapisu przy niewielkich rozmiarach wejścia/wyjścia (I/O), gdzie dominującym atrybutem wydajności jest I/O O operacji na sekundę (IOPS). Woluminy oparte na dyskach twardych (st1 i sc1) są zoptymalizowane pod kątem dużych obciążeń strumieniowych, w których dominującym atrybutem wydajności jest przepustowość. Wszystkie woluminy EBS dobrze sprawdzają się jako pamięć masowa dla systemów plików, baz danych lub dowolnych aplikacji, które wymagają dostępu do nieprzetworzonej, niesformatowanej pamięci masowej na poziomie bloków i obsługują dynamiczne zmiany konfiguracji.
Ze względu na to, że klienci nieustannie dążą do optymalizacji wydatków na chmurę, ważne jest również, aby zidentyfikować nie tylko właściwy typ woluminu pamięci masowej Amazon EBS, ale także optymalną konfigurację woluminu, aby spełnić wymagania wydajnościowe obciążeń roboczych przy jednoczesnym obniżeniu kosztów. Typ woluminu Amazon EBS Throughput Optimized HDD (st1) zapewnia ułamek kosztów typów woluminów opartych na dyskach SSD i może przyspieszyć do 250 MiB/s na TiB z maksymalnie 500 MiB/s na wolumin i podstawową przepustowością 40 MiB/s na TiB. Ze względu na swoje atrybuty wydajności st1 dobrze nadaje się do dużych, sekwencyjnych obciążeń, takich jak Amazon EMR, ETL (wyodrębnianie, przekształcanie, ładowanie), hurtownie danych i przetwarzanie dzienników.
HDFS and Amazon EBS st1 volumes
HDFS składa się z NameNodes i DataNodes. Ponieważ węzły danych działają na sprzęcie wykorzystującym surowe dyski, prawdopodobieństwo awarii któregokolwiek z węzłów jest wysokie. HDFS może replikować dane w kilku węzłach w zależności od współczynnika replikacji. HDFS ma domyślny współczynnik replikacji równy 3, co oznacza, że dane są replikowane trzykrotnie w DataNodes.
W systemie HDFS każdy plik jest dzielony na bloki danych o domyślnym rozmiarze 128 MB, a operacje wejścia/wyjścia są sekwencyjne. Następnie te bloki danych są przechowywane w węzłach danych w sposób rozproszony i replikowane w węzłach. Ze względu na charakter dużych rozmiarów bloków i sekwencyjnego wejścia/wyjścia, woluminy st1 są dobrze dopasowane, ponieważ zapewniają wysoką ciągłą przepustowość sekwencyjnego wejścia/wyjścia przy niższych kosztach niż inne typy woluminów EBS.
Twórcy wykorzystali test porównawczy TestDFSIO do symulacji testu odczytu i zapisu. Poniżej znajdziesz wyniki testów w trzech rozmiarach klastrów. Użyli R5.xlarge (4 vCPU i 32 GiB pamięci) jako typ instancji EC2, z konfiguracją klastra 1 NameNode i 5 DataNodes. W pierwszych dwóch kolumnach poniższej tabeli widać, że każdy węzeł ma inną konfigurację woluminów st1 z całkowitym rozmiarem klastra równym 10 TiB. Konfiguracja testowa obejmuje 400 plików po 4 GB każdy.
| St1 volumes* attached to each DataNode | Size of storage of entire cluster | Test execution time for reads (seconds) | Test execution time for writes (seconds) | Cluster read throughput (MiB/s) |
Cluster write throughput (MiB/s) |
Cost/month |
|---|---|---|---|---|---|---|
|
4 Volumes of |
4*512MiB*5 = 10 TiB |
1452 | 1794 | 1128.37 | 913.26 | $90 |
|
2 Volumes of |
2*1 TiB * 5 |
1384 |
1673 |
1183.81 |
979.31 |
$90 |
| 1 Volume of 2TiB each |
1*2 TiB * 5 = 10TiB |
1249 | 1503 | 1311.76 | 1090.08 |
$90 |
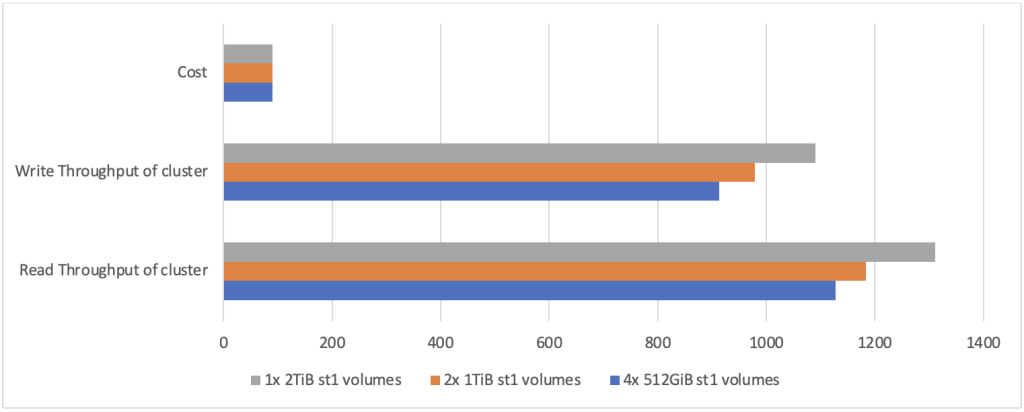
Należy pamiętać, że wraz ze wzrostem rozmiaru pojedynczego woluminu EBS st1 może on zacząć obsługiwać dłuższą stałą przepustowość. Jednak powyżej 2 TiB, ponieważ przepustowość w trybie burst wynosi obecnie 500 MB/s, korzyści wynikające z wykorzystania wydajności w trybie burst będą się utrzymywać. Jednak nadal może utrzymać co najmniej stałą podstawową przepustowość 40 MiB/s na TiB do 12,5 TiB. Gdy rozmiar woluminu osiągnie 12,5 TiB, podstawowa przepustowość jest równa przepustowości serii 500 MiB/s dla tego woluminu. W związku z tym wydajność poza tym rozmiarem woluminu pozostaje taka sama.
Sprawdzanie wydajności za pomocą wskaźników Amazon CloudWatch
AWS udostępnia narzędzie do monitorowania w postaci metryk Amazon CloudWatch, które pozwalają monitorować metryki wydajności Amazon EBS i kontekstualizować zachowanie aplikacji. Możesz znaleźć te metryki, najpierw logując się do AWS Management Console, następnie wyszukując CloudWatch na pasku wyszukiwania, a na końcu przechodząc do Wszystkie metryki > EBS.

Aby obliczyć przepustowość odczytu i zapisu woluminu EBS, użyj niestandardowej matematyki CloudWatch w następujący sposób:
- Read Throughput = SUM(VolumeReadBytes)/ Period (in seconds)
- Write Throughput = SUM(VolumeWriteBytes)/ Period (in seconds)
W poniższej sekcji autorzy porównają wydajność przepływności woluminów st1 w trzech konfiguracjach, aby określić, która konfiguracja zapewnia najlepszą wydajność cenową.
Przepustowość odczytu woluminów st1 w trzech konfiguracjach
Patrząc na przepustowość odczytu, wolumen 512 GiB może osiągnąć wartość szczytową ~ 75 MiB/s, wolumen 1-TiB może osiągnąć wartość szczytową ~ 180 MiB/s, a wolumen 2-TiB może osiągnąć wartość szczytową 375 MiB /s przepustowości odczytu.

Zapisz przepustowość woluminów st1 w trzech konfiguracjach
Następnie przyjrzyj się przepustowości zapisu. Wolumin 512-GiB może osiągnąć szczytową wartość ~125 MiB/s, wolumen 1-TiB może osiągnąć szczytową ~250 MiB/s, a wolumen 2-TiB może osiągnąć szczytową przepustowość zapisu 500MiB/s.

W wyniku obserwacji z powyższych wykresów CloudWatch dotyczących przepustowości odczytu/zapisu można stwierdzić, że większe woluminy st1 mogą zwiększyć wydajność. Wynika to z faktu, że wydajność woluminu st1 jest wprost proporcjonalna do skonfigurowanej pamięci masowej przy 40 MiB/s na TiB. Jest to również zgodne z danymi, które obserwujesz z powyższej tabeli, gdzie przepustowość klastra wzrasta wraz ze wzrostem rozmiaru poszczególnych woluminów st1 w tym klastrze.
Bilans salda woluminów st1 w trzech konfiguracjach
Bilans serii informuje nas o pozostałych kredytach przepustowości woluminów st1 w zasobniku serii, co pozwala na zwiększenie wydajności woluminów powyżej ich wydajności bazowej. Wskazuje, jak szybko woluminy st1 wyczerpują swoje kredyty przepustowości w czasie. Z poniższego wykresu widać, że wolumin 512-GiB jako pierwszy spadł do 0, a następnie wolumin 1-TiB, a następnie wolumen 2-TiB. Pokazuje to, że większe woluminy st1 mogą utrzymać wyższą wydajność w porównaniu z mniejszymi woluminami st1.

Wnioski
W tym artykule autorzy skonfigurowali trzy klastry Amazon EMR, z których każdy ma inną konfigurację woluminu st1 w środowisku testowym i porównali ich wyniki wydajności podczas uruchamiania systemu plików HDFS. Na podstawie wskaźników CloudWatch można wywnioskować, że używając większych wolumenów st1 w klastrze Amazon EMR z systemem HDFS, można uzyskać wyższą przepustowość przy takim samym koszcie wielu mniejszych wolumenów st1, optymalizując w ten sposób wydajność cenową. Amazon EBS zapewnia klientom elastyczność wyboru rozwiązania pamięci masowej, które spełnia i skaluje się zgodnie z wymaganiami dotyczącymi obciążenia HDFS. St1 jest dostępny dla wszystkich regionów AWS i możesz uzyskać dostęp do konsoli zarządzania AWS, aby uruchomić swój pierwszy wolumen st1 lub przekonwertować istniejące wolumeny, postępując zgodnie z tym przewodnikiem.
Źródło: AWS

