




Pojazdy autonomiczne (AV) muszą przejechać setki milionów mil – a czasem setki miliardów mil – aby zademonstrować swoją niezawodność pod względem ofiar śmiertelnych i obrażeń. Istnieje zapotrzebowanie na alternatywne metody uzupełniające testy w świecie rzeczywistym, w tym testy i symulacje wirtualne, modelowanie i analizę matematyczną oraz testowanie scenariuszy i zachowań.
W tej sesji AWS re:Invent można dowiedzieć się, jak BMW Group zbiera ponad 1 miliard kilometrów anonimowych danych percepcyjnych ze swojej światowej floty pojazdów klientów, aby opracować bezpieczne i wydajne systemy zautomatyzowanej jazdy.
Aby wesprzeć swoich klientów z branży motoryzacyjnej w rozwiązywaniu tych problemów, autorzy najpierw stworzyli architekturę referencyjną dla jeziora danych zaawansowanych systemów wspomagania kierowcy (ADAS), opisaną w artykule na blogu poświęconym architekturze AWS. Opracowali również serię blogów z repozytoriami GitHub, aby omówić kluczowe aspekty:
- Automated scene detection pipeline;
- Running workload on Amazon Managed Workflow for Apache Airflow (MWAA);
- Automated image processing and model training pipeline;
- Visualization of ROS Bag Data.
Autonomous Driving Data Framework (ADDF) aktualnie uprzemysławia rozwiązanie referencyjne i oferuje wstępnie zbudowane dane przykładowe, scentralizowane przechowywanie danych, potoki przetwarzania danych, mechanizmy wizualizacji, interfejs wyszukiwania, obciążenie symulacyjne, interfejsy analityczne i gotowe pulpity nawigacyjne. Celem jest przetwarzanie i dostarczanie możliwych do wyszukania, wysoce dokładnych, oznaczonych danych opartych na scenariuszach dla dalszych obciążeń, w tym trenowanie modeli, generowanie danych syntetycznych i symulacja.
Przypadek użycia i omówienie rozwiązania
Pierwsza wersja ADDF obejmuje następujące cztery przypadki użycia (Rysunek nr 1):
- Wykrywanie i wyszukiwanie scen: Po pozyskaniu danych z każdego pozyskanego pliku zostaną wyodrębnione metadane, a potok wykrywania scen określi interesujące sceny, takie jak scenariusze „osoba na danym pasie”. Wykryte metadane sceny są przechowywane w Amazon DynamoDB i udostępniane za pośrednictwem usługi Amazon OpenSearch, która umożliwia użytkownikom znajdowanie i lokalizowanie odpowiednich danych wejściowych w jeziorze danych na podstawie metadanych sceny.
- Wizualizacja danych: ADDF zapewnia moduł wizualizacji danych oparty na Webviz, który może przesyłać strumieniowo pliki worków ROS z jeziora danych i wizualizować je w przeglądarce. Moduł wizualizacji obsługuje strumieniowanie określonych scen wykrytych w poprzednim kroku i umożliwia użytkownikom weryfikację lub debugowanie plików torby ROS.
- Symulacja: Dzięki ADDF użytkownicy mogą uruchamiać swoje konteneryzowane obciążenia na dużą skalę na pozyskiwanych danych. Moduł symulacji zapewnia wysokopoziomową orkiestrację przepływów pracy przy użyciu przepływów pracy zarządzanych przez Amazon dla Apache Airflow (Amazon MWAA), które delegują zadania symulacji wymagające dużej mocy obliczeniowej do dedykowanych usług zoptymalizowanych pod kątem skalowalnego przetwarzania równoległego, takich jak AWS Batch lub zarządzana usługa Kubernetes, Amazon Elastic Kubernetes Service (Amazon). EKS).
- Rozwój i wdrażanie: Bootstrapping, rozwój i wdrażanie modułów 1-3 są możliwe dzięki wykorzystaniu projektów open-source AWS CodeSeeder i SeedFarmer. CodeSeeder wykorzystuje AWS CodeBuild do zdalnego wdrażania poszczególnych modułów. Umożliwia to tworzenie modułów przy użyciu wspólnej infrastruktury jako kodu i mechanizmów wdrażania, takich jak AWS Cloud Development Kit (AWS CDK), AWS CloudFormation, Terraform i inne. SeedFarmer wykorzystuje deklaratywne manifesty do definiowania wdrożenia ADDF i koordynuje wdrażanie, niszczenie, wykrywanie zmian i zarządzanie stanem modułu. SeedFarmer umożliwia automatyczne zarządzanie wdrożeniami ADDF przez GitOps.

Rysunek 1: Przypadki użycia ADDF
Ta architektura rozwiązania (rysunek nr 2) składa się z sześciu kluczowych elementów:
- Interfejs użytkownika do tworzenia kodu (AWS Cloud9), raportowanie KPI (Amazon QuickSight), aplikacja internetowa do wyszukiwania i wizualizacji scenariuszy, narzędzie do wdrażania (SeedFarmer CLI) i modelowania (Jupyter Notebook).
- Trzy gotowe przepływy pracy obejmują wykrywanie i wyszukiwanie scen, wirtualizację plików Rosbag, symulację za pomocą EKS. Na planie znajdują się trzy dodatkowe przepływy pracy: uczenie modeli, automatyczne etykietowanie i obliczanie KPI.
- Usługa orkiestracji to Amazon MWAA z elastycznym zapleczem obliczeniowym (AWS Batch, Amazon EKS i Amazon EMR).
- Przechowywanie metadanych obejmuje AWS Glue Data Catalog dla danych dysku, Amazon Neptune dla pochodzenia plików i danych, Amazon DynamoDB dla metadanych dysku oraz Amazon OpenSearch Service dla OpenScenario Search.
- Amazon Simple Storage Service (Amazon S3) to magazyn danych dla surowych danych, a Amazon Redshift to magazyn danych dla danych z czujników numerycznych.
- Automatyzacja CI/CD wykorzystuje AWS CDK, AWS CodeBuild i AWS CodeSeeder.

Rysunek 2: Omówienie rozwiązania ADDF
Wdrażanie nieprodukcyjnego środowiska ADDF z Demo NoteBook
Wymagania wstępne
Aby uprościć wdrażanie i zmniejszyć liczbę zależności i wymagań wstępnych, ADDF wykorzystuje dwa projekty AWS typu open source: CodeSeeder, aby umożliwić zdalne wykonanie kodu Python w AWS CodeBuild i SeedFarmer, aby zaaranżować wdrażanie modułów ADDF przez CodeSeeder.
Korzystając z CodeSeeder i SeedFarmer, jesteś w stanie zredukować lokalne wymagania do:
- wersji Python 3.7 lub lepszej;
- git CLI;
- AWS Credentials;
- AWS CLI;
- aws-cdk CLI version 2.20.
Wdrażanie
Krok 1: Sklonuj repozytorium ADDF z GitHub. Autorzy zalecają sprawdzenie najnowszej, oficjalnej edycji wydania. Ponieważ ADDF ma być zarządzany przez zautomatyzowane procesy CI/CD powiązane z własnymi repozytoriami git klienta, autorzy sugerują również ustawienie zdalnego repozytorium GitHub jako zdalnego.
git clone --origin upstream --branch release/0.1.0 https://github.com/awslabs/autonomous-driving-data-framework
Krok 2: Utwórz środowisko wirtualne Pythona i zainstaluj zależności.
cd autonomous-driving-data-framework
python3 -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
Upewnij się, że posiadasz prawidłowe kwalifikacje AWS, ustaw domyślny region i uruchom CDK. Bootstrapping CDK jest wymagany tylko wtedy, gdy AWS CDK nie był wcześniej używany na koncie/regionie.
export AWS_DEFAULT_REGION=<<REGION>>
cdk bootstrap aws://<<ACCOUNT_NUMBER>>/<<REGION>>Krok 3: Skonfiguruj klucze tajne w Menedżerze tajnych AWS, które będą używane przez ADDF; są one następujące:
- JupyterHub;
- VS Code;
- OpenSearch Proxy;
- Docker Hub (optional).
Autorzy udostępniają skrypty ułatwiające konfigurację (pierwszy skrypt wykorzystuje narzędzie jq):
source ./scripts/setup-secrets-example.sh # This sets up the first three credentials. ./scripts/setup-secrets-dockerhub.sh # This will prompt for username and password.
Krok 4: Wybierz moduły i rozpocznij wdrażanie. ADDF składa się z różnych modułów i możesz wybrać, które moduły chcesz włączyć w tzw. manifeście. Kilka przykładowych manifestów zostało udostępnionych w folderze ./manifests. Zawsze zaleca się tworzenie kopii manifestów specyficznych dla środowiska przy użyciu przykładowych manifestów.
cp -R manifests/example-dev manifests/demo sed -i .bak "s/example-dev/demo/g" manifests/demo/deployment.yaml
W instruktażu autorzy użyją folderu demo, który posiada manifest deployment.yaml jako sterownik wdrażania modułów. Dostosowując manifest, możesz wybrać moduły, które chcesz uwzględnić we wdrożeniu ADDF. Więcej szczegółowych opcji konfiguracyjnych można znaleźć w dokumentacji w repozytorium. Dla uproszczenia twórcy korzystają z dostarczonego manifestu i wdrażają go:
seedfarmer apply ./manifests/demo/deployment.yaml
Gdy wdrożenie zakończy się pomyślnie w wyniku wykonania poprzedniego polecenia, zobaczysz wdrożone moduły ADDF, jak pokazano na rysunku 3.

Rysunek 3: Przegląd wdrożonych modułów
Demonstracyjny przypadek użycia
Zaloguj się do JupyterHub
Po pomyślnym wdrożeniu możesz uzyskać dostęp do modułu JupyterHub wdrożonego w Amazon EKS i postępować zgodnie z poniższymi instrukcjami, aby uzyskać dostęp do pulpitu nawigacyjnego JupyterHub:
JupyterHub jest zalecany tylko w przypadku obciążeń związanych z wersją demo i nie jest zalecany w przypadku interakcji klasy produkcyjnej z danymi/usługami obejmującymi dane produkcyjne. Autorzy Zalecają korzystanie z Amazon EMR Studio w przypadku wszelkich obciążeń niezwiązanych z wersją demo.
1. Otwórz konsolę Amazon EC2 na https://console.aws.amazon.com/ec2/.
2. Na pasku nawigacyjnym wybierz region, w którym wdrożono ADDF, aby pobrać DNS modułu równoważenia obciążenia utworzonego dla JupyterHub.
3. Wybierz system równoważenia obciążenia, który zaczyna się od k8s-jupyter, jak pokazano poniżej:
k8s-jupyterh-jupyterh-XXXXXXXXX.us-west-2.elb.amazonaws.com4. Skopiuj nazwę DNS równoważnika obciążenia i dołącz do niego jupyter, poniżej wygląda to tak:
k8s-jupyterh-jupyterh-XXXXXXXXX.us-west-2.elb.amazonaws.com/jupyter5. Następnie zostaniesz poproszony o wprowadzenie nazwy użytkownika i hasła JupyterHub, które zostały pierwotnie utworzone przy użyciu skryptu pomocniczego setup-secrets-example.sh i przechowywane w AWS Secrets Manager. Można je pobrać z konsoli AWS Secrets Manager, a następnie wybrać poświadczenia jh z paska wyszukiwania i pobrać poświadczenia.
6. Po zalogowaniu się do środowiska JupyterHub możesz utworzyć przykładowy notatnik.
Uruchom strumień wykrywania scen
1. Możesz pobrać dwa publicznie dostępne przykładowe pliki ROS (plik 1 i plik 2) i skopiować je do zasobnika, który zostałby wdrożony przez moduł datalake-buckets. Możesz zidentyfikować nazwę zasobnika za pomocą wzorca nazewnictwa addf-demo-raw-bucket-<> i skopiować je do `rosbag-scene-detection`
2. Po przesłaniu powyższych plików zostanie wyzwolony moduł wykrywania sceny oparty na AWS Step Functions i powinieneś spodziewać się tabel DynamoDB specyficznych dla modułu, a mianowicie Rosbag-BagFile-Metadata i Rosbag-Scene-Metadata, wypełnionych wyniki. Poniżej znajduje się zrzut ekranu (Rysunek 4) pomyślnego uruchomienia potoku wykrywania scen.

Rysunek 4: Potok wykrywania scen z funkcjami krokowymi AWS.
3. Warunkiem wstępnym uruchomienia poniższych poleceń w notatniku JupyterHub jest zainstalowanie kilku plików binarnych, jak poniżej:
pip install boto3 pandas awscli
4. Możesz wykonać poniższe polecenie, aby przeszukać domenę OpenSearch i uzyskać listę tabel:
wget -qO- \
--no-check-certificate \
https://vpc-addl-example-dev-core-opens-
<<XXXXXXXX>>.<<region>>.es.amazonaws.com
/_cat/indices?h=indexPowinieneś zastąpić domenę OpenSearch i nazwę tabeli w powyższym poleceniu fizycznymi identyfikatorami wdrożonymi na Twoim koncie i regionie.
5. Wybierz tabelę (skopiuj nazwę tabeli), która zaczyna się od rosbag-metadata-scene-search-<> i utwórz poniższe zapytanie:
wget -qO- \
--output-document=query_results.json \
--no-check-certificate \
"https://vpc-addl-example-dev-core-opens-
<<XXXXXXXX>>.<<region>>.es.amazonaws.com/rosbag-metadata-
scene-search--<<date>>/_search?pretty=true”Powinieneś zastąpić domenę OpenSearch i nazwę tabeli w powyższym poleceniu fizycznymi identyfikatorami wdrożonymi na twoim koncie i regionie.
Ten przypadek użycia zapewnia kompleksowy potok wykrywania scen dla plików ROS, pozyskując pliki ROS z S3 i przekształcając dane tematu do formatu parkietu, aby przeprowadzić wykrywanie scen w PySpark w Amazon EMR. To z kolei udostępnia opisy scen za pośrednictwem DynamoDB do Amazon OpenSearch.
Wizualizacja pliku ROS bag
Możesz wysłać zapytanie do prywatnego interfejsu API REST obsługiwanego przez Amazon API Gateway, aby wygenerować punkt końcowy Webviz, a następnie skonstruować punkt końcowy, dołączając parametry ciągu zapytania scene-id i record-id w celu uzyskania podpisanego adresu URL.
wget -qO- \
"https://XXXXXX.execute-api.<<region>>.amazonaws.com/get-
url?scene_id=small2__2020-11-19-16-21-
22_4_PersonInLane_1.6058245149E9&record_id=small2__2020-11-19-
16-21-22_4"Powinieneś zastąpić łącze Private REST API w powyższym poleceniu fizycznym identyfikatorem wdrożonym na Twoim koncie i regionie.
Następnie skopiuj wartość klucza url z treści odpowiedzi i otwórz ją w przeglądarce Google Chrome (preferowane). Po załadowaniu adresu URL niestandardowe układy dla Webviz można zaimportować za pomocą konfiguracji JSON. Ten niestandardowy układ zawiera konfiguracje tematów i układy okien specyficzne dla naszego formatu torby ROS i powinien być modyfikowany zgodnie z tematami ROS. Postępuj zgodnie z poniższymi wskazówkami:
- Wybierz Config → Import/Export Layout
- Skopiuj i wklej zawartość layout.json z modules/visualization/layout.json do wyskakującego okienka i odtwórz zawartość
Powinieneś zobaczyć przykładową wykrytą scenę, jak na rysunku nr 5.
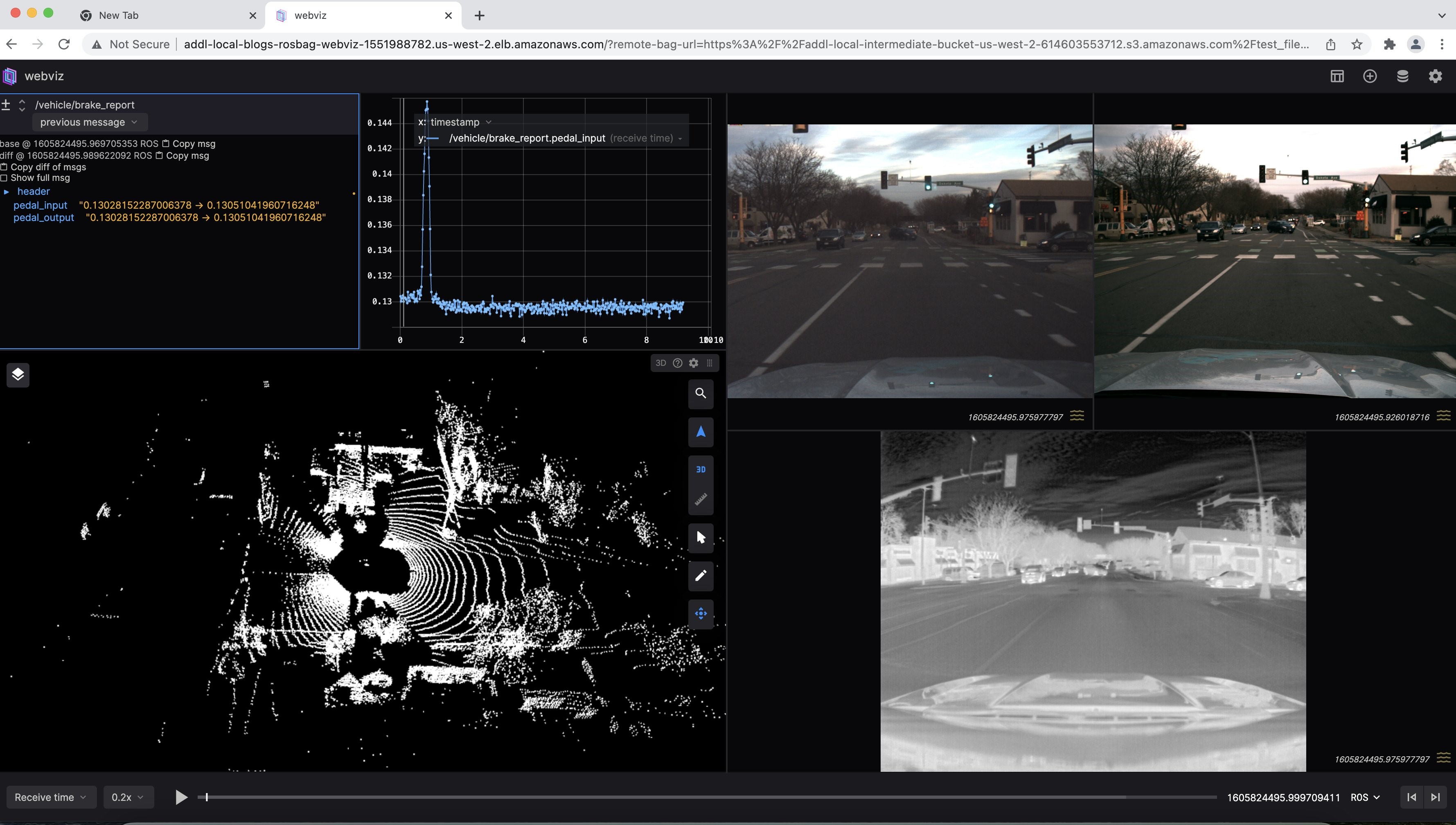
Rysunek 5: Przykładowa wizualizacja pliku torby ROS przesyłanego strumieniowo z Amazon S3
Dostosuj potoki
Baza kodu jest podzielona na segmenty do zarządzania. Wdrożenie składa się z grup, które z kolei są złożone z modułów. Moduły zawierają kod, podczas gdy grupy i wdrażanie służą do logicznej separacji. Moduły mogą wykazywać zależności od innych modułów (na przykład moduł sieciowy może być ponownie używany przez inne moduły), które należą do różnych grup, ale moduły zadeklarowane jako część grupy nie mogą deklarować swoich zależności w ramach tej samej grupy. Grupy są wdrażane w określonej kolejności i są niszczone w odwrotnej kolejności, aby natywnie obsługiwać zależności. Decydując o liście modułów i ich kolejności, kolejność ma kluczowe znaczenie (na przykład należy wdrożyć moduł sieciowy przed wdrożeniem zasobów obliczeniowych wymagających VPC). Każdy moduł może zdefiniować parametry wejściowe do dostosowywania i parametry wyjściowe, które mają być wykorzystywane przez inne moduły, co daje modułom bazy kodu poziom oddzielenia od siebie. Innymi słowy, możesz zmodyfikować wdrożony moduł (na przykład poprzez dodanie nowej funkcjonalności lub zmianę parametru wejściowego) bez wpływu na inne moduły w tym samym wdrożeniu, gdzie SeedFarmer CLI wykryje zestaw zmian i odpowiednio go wykona bez wpływu na moduły zależne.
Manifesty określają dane wejściowe dla każdego modułu w projekcie. Istnieje podstawowy manifest (deployment.yaml na rysunku nr 6), który steruje nazwą wdrożenia (znaną również jako projekt), grupami i ich kolejnością we wdrożeniu oraz miejscem, w którym można znaleźć manifesty dla każdej grupy.

Rysunek 6: Główny plik manifestu
Każdy manifest grupy definiuje moduły, w których znajduje się kod, oraz ich parametry wejściowe w formacie klucz-wartość (w tym miejscu można również odwoływać się do danych wyjściowych modułu z innej grupy).

Rysunek 7: Plik manifestu danego modułu
Teraz, gdy posiadasz już podstawową wiedzę, pora przyjrzeć się, jakie może to mieć dla Ciebie korzyści. Moduł rosbag-scene-detection jest zdefiniowany w manifestach manifests/demo/rosbag-modules.yaml (Rysunek 7) a kod znajduje się w module modules/analysis/rosbag-scene-detection. Jeśli chcesz zmodyfikować kod, na przykład dodać nowy krok przetwarzania danych po wdrożeniu modułu, możesz dodać zmiany w kodzie i zapisać je. Aby zmiany odniosły skutek i zostały wdrożone, musisz ponownie uruchomić wdrożenie z terminala:
seedfarmer apply ./manifests/demo/deployment.yamlSeedFarmer wykryje, że nastąpiła zmiana w bazie kodu dla tego modułu i ponownie wdroży ten moduł. W tle SeedFarmer porównuje zawartość deployment.yaml z tym, co jest już wdrożone i stosuje zmiany (w kolejności określonej w deployment.yaml). Ponieważ każdy moduł posiada poziom oddzielenia, tylko te moduły, które zostały zmienione, zostaną ponownie wdrożone, pozostawiając niezmienione moduły w spokoju.
Porządkowanie
Aby zniszczyć moduły dla danego wdrożenia demo, możesz uruchomić poniższe polecenie:
seedfarmer destroy demoPowinieneś zastąpić wersję demo ciągu ustawioną nazwą środowiska, jeśli została dostosowana. Możesz przekazać opcjonalny znacznik --debug do powyższego polecenia, aby uzyskać dane wyjściowe poziomu debugowania.
Perspektywy i wnioski
ADDF to gotowa do użycia platforma typu open source do obsługi obciążeń ADAS. Najpierw opisano jej architekturę i przypadki użycia, które obejmuje. Po drugie, pokazano, jak wdrożyć ADDF od podstaw, aby szybko rozpocząć pracę. Finalnie zaprezentowano, jak dostosować potok wykrywania scen do indywidualnych potrzeb.
Plan strategii testowej dostarczony przez grupę badawczą ASAM Test Specification określił metody testowe i przypadki użycia do walidacji funkcji AV i prowadzenia pojazdu w sposób bezpieczny i niezawodny. ADDF obejmuje metody testowe, w tym test oparty na scenariuszach i wstrzykiwanie błędów. Autorzy dążą do rozszerzenia i dalszego rozwoju ADDF, aby sprostać wymaganiom swoich klientów – więcej przepływów pracy, wielodostępność i syntetyczne generowanie scen, aby wymienić tylko kilka.
Producenci OEM, dostawcy Tier-N i start-upy mogą skorzystać z tego rozwiązania typu open source. Twórcy mocno wierzą w open-source, cenią opinie i wkład społeczności.
źródło: AWS
