




W tym artykule poznasz wykrywanie anomalii Amazon CloudWatch i skonfigurujesz je za pomocą konsoli AWS, interfejsu wiersza poleceń AWS (AWS CLI) i AWS CloudFormation. Wraz z autorami przeanalizujesz również niektóre najlepsze praktyki dotyczące wykrywania anomalii w CloudWatch.
Alarmy CloudWatch umożliwiają obserwowanie metryk CloudWatch i otrzymywanie powiadomień, gdy metryki wykroczą poza skonfigurowane poziomy (wysokie lub niskie progi). Wykrywanie anomalii CloudWatch optymalizuje tę możliwość, unikając ręcznej konfiguracji, zapewniając jednocześnie możliwość dostosowania i ponownej kalibracji progów operacji.
CloudWatch anomaly detection stosuje algorytmy statystyczne i uczenia maszynowego (ML) do metryk CloudWatch, oblicza normalne linie bazowe i minimalizuje anomalie powierzchniowe przy minimalnej interwencji użytkownika. Rozważ przykład firmy FinTech. Firma spodziewa się dużego ruchu w godzinach rynkowych, co przekłada się na wysokie wykorzystanie procesora. Nie spodziewaliby się takiego zachowania późno w nocy. Wykrywanie anomalii Cloudwatch uczy się tych wzorców i inteligentnie generuje przydatne alerty, na których zależy Twojemu zespołowi. Ta funkcja pomaga zespołowi operacyjnemu unikać szumów powodowanych przez alarmy CloudWatch i daje pewność, że alarm jest wykonalny. Firma FinTech może również wysyłać metryki, takie jak liczba transakcji kartą kredytową tygodniowo, do wykrywania anomalii CloudWatch. Pozna tygodniowe progi i automatycznie wykryje nietypowy skok liczby transakcji.
W tym artykule szczegółowo opisano, jak analizować dzienniki zapory sieciowej i wykrywać anomalie w celu tworzenia alarmów na podstawie nieprawidłowej aktywności sieciowej.
Włączanie wykrywania anomalii
Wykrywanie anomalii CloudWatch jest dostępne w przypadku dowolnej metryki usługi AWS lub niestandardowej metryki CloudWatch, która ma dostrzegalny trend lub wzorzec. Analizuje wartości historyczne dla wybranej metryki pod kątem przewidywalnych wzorców, które powtarzają się w czasie, aby utworzyć linię bazową. Ten model linii bazowej jest aktualizowany po zaobserwowaniu nowych danych metrycznych, co zmniejsza potrzebę częstych interwencji ręcznych. Ponadto będzie okresowo oceniać wydajność modelu i ponownie go szkolić, aby dostosować się do zmieniających się wskaźników biznesowych.
Aby skonfigurować wykrywanie anomalii, możesz użyć konsoli CloudWatch, AWS CLI lub CloudFormation/AWS Cloud Development Kit (AWS CDK). Każdy z nich jest opisany w następujący sposób.
Konsola
Wykrywanie anomalii można włączyć jednym kliknięciem w konsoli CloudWatch, zmniejszając w ten sposób wysiłek potrzebny do włączenia tej funkcji. Na stronie CloudWatch Metrics możesz włączyć wykrywanie anomalii, wybierając ikonę Pulse.

Rysunek 1: Ten obraz pokazuje, jak włączyć wykrywanie anomalii, wybierając ikonę Pulse
Wybranie ikony Pulse umożliwia wykrywanie anomalii w metryce TargetResponseTime, jak pokazano na poniższej ilustracji. Oczekiwane wartości są wyświetlane na szarym pasku, a nieprawidłowe wartości są wyświetlane na czerwono.

Rysunek 2. Ten obraz przedstawia wykrywanie anomalii włączone w metryce TargetResponseTime, w tym szary pasek, który ilustruje oczekiwany zakres wartości i anomalię na czerwono.
Ponadto możesz dostosować wykrywanie anomalii, ustawiając czułość, aby w razie potrzeby dostosować przepustowość. Im większa wartość czułości, tym szersze pasma, co zwiększa zakres oczekiwanych wartości. Ta opcja jest realizowana za pomocą wyrażenia matematycznego metryki przy użyciu funkcji ANOMALY_DETECTION_BAND. Ta funkcja tworzy pasma wykrywania anomalii (szary obszar wokół szeregów czasowych metryki ograniczony przez pasma Wysoki i Niski).
Przyjmuje następujące dwa parametry:
- Pierwszym argumentem jest nazwa metryki (m1 na poniższej ilustracji), która identyfikuje metryki umożliwiające wykrywanie anomalii.
- Drugim argumentem jest liczba odchyleń standardowych dla pasma. Wyższe odchylenia standardowe zwiększą szerokość pasma. Czułość pasma wykrywania anomalii można dostroić, modyfikując drugi argument modelu wykrywania anomalii.
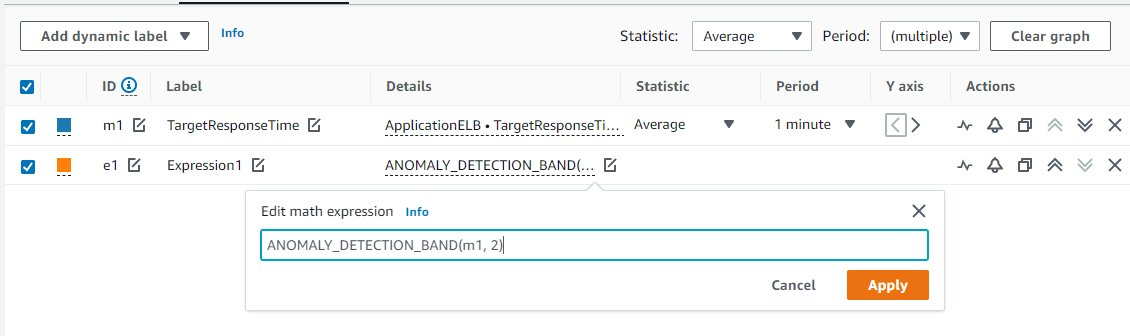
Rysunek 3: Ten obraz przedstawia sposób dostosowania wykrywania anomalii za pomocą funkcji matematycznej metryki ANOMALY_DETECTION_BAND.
Wybierz Zastosuj, aby zapisać zaktualizowaną funkcję.
AWS CLI
Detektor anomalii może zostać utworzony przez wywołanie metody PutAnomalyDetector. Oto przykładowe żądanie:
aws cloudwatch put-anomaly-detector --namespace
"AWS/ApplicationELB" --metric-name "RequestCount" --dimensions
Name="LoadBalancer",Value="sample-ALB-name" --stat "Sum"Możesz także wywołać interfejs API DescribeAnomalyDetector, aby wyświetlić aktywne detektory anomalii i użyć interfejsu API DeleteAnomalyDetector, aby usunąć detektor anomalii.
CloudFormation i AWS CDK Templates
Możesz także utworzyć detektor anomalii za pomocą szablonów CloudFormation/AWS CDK. Co więcej, możesz utworzyć stos i dodać następujące skrypty, aby utworzyć detektor anomalii i alarm:
// The code below demonstrates how to instantiate this type. // The values are placeholders you should change. import { Stack, StackProps } from 'aws-cdk-lib'; import { Construct } from 'constructs'; import * as cdk from 'aws-cdk-lib/'; import * as cloudwatch from 'aws-cdk-lib/aws-cloudwatch'; export class HelloCdkStack extends Stack { constructor(scope: Construct, id: string, props?: StackProps) { super(scope, id, props); const cfnAnomalyDetector = new cloudwatch.CfnAnomalyDetector(this, 'MyCfnAnomalyDetector',{ dimensions: [{ name: 'TargetGroup', value: 'targetgroup/Servi-lista-1D0KN7TZSE1NN/b68d0001217cb52c', }], metricName: 'RequestCountPerTarget', namespace: 'AWS/ApplicationELB', stat: 'Sum' }); } }
Model wykrywania anomalii
Model wykrywania anomalii dostosowuje się do trendów metrycznych, a metryki wydajności wykazują spójność w codziennych operacjach. Wykrywanie anomalii może dostosować się do tak powolnego, długoterminowego trendu, że nie ma potrzeby ręcznego dostosowywania progów alarmowych.

Rysunek 4: Ten obraz przedstawia wykrywanie anomalii dostosowujące się w czasie wraz ze zmianami wykorzystania zasobów.
Anomaly detection identyfikuje wzorce metryk, od godzinowych, dziennych lub tygodniowych. Uwzględnia zidentyfikowane wzorce w modelu w celu wygenerowania pasm. Algorytm wykrywania anomalii CloudWatch szkoli się na danych metrycznych z maksymalnie dwóch tygodni. Można go jednak włączyć dla metryki, nawet jeśli nie ma danych z pełnych dwóch tygodni. Poniżej przedstawiono przykład pasm wykrywania anomalii dla metryk z okresami jednodniowymi. Wykrywanie anomalii nie trwa obecnie dłużej niż dwa tygodnie i nie może modelować jednorazowych wydarzeń, takich jak Czarny piątek. Ponadto nie może iterować na danych dłuższych niż dwa tygodnie.

Rysunek 5: Ten obraz pokazuje, jak wykrywanie anomalii uwzględnia sezonowość i trendy w metrykach.
Podczas uczenia modelu można wykluczyć zakresy czasu. Ta funkcja umożliwia trenowanie modelu bez nietypowych wartości metryki.
Zwykle istnieją tylko dwa sposoby dostosowania pasm wykrywania anomalii:
- Zmodyfikuj czułość, aby zmienić szerokość pasma bez ponownego uczenia modelu.
- Usuń i ponownie utwórz nowy detektor anomalii, aby ręcznie przeszkolić model.
Załóżmy, że nastąpi nagła zmiana wzorca metrycznego, na przykład skoki średniej wartości mierzonej z 1 do 1000. W takim przypadku dostosowanie pasm wykrywania anomalii do nowego poziomu zajmie trochę czasu, zwykle kilka godzin. W tym okresie może nadal zgłaszać anomalie i powodować fałszywe alarmy.
Używanie Anomaly Detection z alarmami CloudWatch i pulpitami nawigacyjnymi CloudWatch
Pulpity nawigacyjne CloudWatch są cennym zasobem do tworzenia centralnego repozytorium najbardziej krytycznych metryk dla Twojej organizacji. Pracuj w zespole, aby zidentyfikować podstawowe metryki, które mają sens dla Twoich aplikacji. Po włączeniu wykrywania anomalii można tworzyć pulpity nawigacyjne specyficzne dla aplikacji, które wykorzystują widżety, aby każda aplikacja posiadała dostępne metryki. Pulpity nawigacyjne CloudWatch można udostępniać użytkownikom spoza konta AWS, zapewniając w ten sposób zespołom wsparcia szybki dostęp do dowolnych wykreślonych metryk.
Aby upewnić się, że podczas wykrywania anomalii nie zostaną pominięte żadne nieprawidłowe skoki, kluczowe znaczenie ma skonfigurowanie alertów dla najbardziej krytycznych wskaźników. Możesz ustawić odpowiednie alerty w CloudWatch za pomocą Alarmów CloudWatch. Możesz także łączyć wiele alarmów i tworzyć złożone alarmy, które skutkują mniejszymi i bardziej skutecznymi powiadomieniami. Za pomocą matematyki metryk można tworzyć niestandardowe metryki zagregowane. Korzystanie z wykrywania anomalii w połączeniu z matematyką metryk pozwala zdefiniować akceptowalny zakres dla tych niestandardowych metryk. Łączenie obliczeń matematycznych metryk, wykrywania anomalii i alarmów umożliwia tworzenie alertów dynamicznych w oparciu o złożone metryki zamiast polegania na jednej metryce. Korzystanie z alarmów CloudWatch pozwala dostosować działania, które mogą zostać uruchomione, jeśli alarm przejdzie przez regułę CloudWatch Events. Co więcej, możesz wyzwolić środki zaradcze za pomocą funkcji Lambda.
Podsumowanie
Anomaly detection zapewnia wgląd w metryki operacyjne, które umożliwiają identyfikację normalnego wykorzystania zasobów AWS i powiązanych metryk. Pozwala zidentyfikować metrykę, która może być wartością odstającą. Model dynamiczny umożliwia zdefiniowanie zakresu, który pomaga uniknąć fałszywych alarmów, gdy metryka może się zmienić w odpowiedzi na oczekiwane zachowania.
Klienci korzystają dziś z wykrywania anomalii CloudWatch w szerokim zakresie wskaźników. Na przykład często widzimy klientów korzystających z tej funkcji do monitorowania czasu trwania AWS Lambda, wywołań i metryk ograniczania przepustowości. Klienci Amazon Elastic Compute Cloud (Amazon EC2) monitorują CPUUtilization, EBSIOBalance%; Metryki EBSByteBalance%, NetworkIn i NetworkOut. Klienci Amazon Relational Database Service (Amazon RDS) monitorują wskaźniki DatabaseConnections, CPUUtilization i FreeStorageSpace.
Anomaly detection jest ogólnie dostępne i możesz zacząć z niego korzystać już dziś za pośrednictwem konsoli AWS, AWS CLI lub CloudFormation/AWS CDK.
źródło: AWS
