





Jeśli chcesz poznać naszą ofertę, zobacz na czym dokładnie polega nasze Zarządzanie i administracja serwerami.
Zarządzanie serwerami i każdą infrastrukturą IT zaczyna się od monitoringu. Wszystkie czynności, które wykonuje administrator serwerów są podyktowane albo cyklicznością, albo są spowodowane informacjami płynącymi z systemu monitoringu serwerów. To dzięki monitoringowi można wykryć zarówno problemy i awarie, jak i planować rozwój systemu, jego zapotrzebowanie na zasoby, a także przeciwdziałać problemom, śledzić trendy i zmiany obciążenia. Bez danych z monitoringu, szczególnie historycznych, czasem jesteśmy głusi i ślepi w diagnostyce problemów.
Dlatego monitoring to kluczowy element w administracji serwerem i powinien być zrealizowany oraz zaplanowany z dużą uwagą. Lata praktyki i doświadczenie z tysięcy urządzeń nauczyło nas, że każdy monitoring można poprawić i usprawnić oraz, że... nigdy nie jest on dość dobry. W swojej pracy w zarządzaniu serwerami wykorzystujemy system Nagios oraz Prometheus (z dodatkami), znamy też Zabbixa. O ile Nagiosa i Zabbixa znają wszyscy administratorzy, to Prometheus, mimo zdobycia ostatnio dużej popularności, nie jest aż takim oczywistym wyborem.
Czym jest Prometheus?
Prometeusz to ekosystem do monitoringu zdarzeniowego i alertowania. Ten ekosystem składa się z kilku aplikacji. Głównej, od której pochodzi nazwa całego systemu, czyli Prometheus - jest to baza danych szeregów czasowych (https://pl.wikipedia.org/wiki/Szereg_czasowy) - TSDB (time series database) pobieranych za pomocą https. Zawiera ona również bardzo mocno zaawansowany język zapytań PromQL, pozwalający na wybieranie i agregacje tych szeregów - używany głównie do definicji alertów. Drugą aplikacją jest AlertManager - odpowiedzialny za obsługę alertów - ich grupowanie, eskalacje, tłumienia i rutowanie ich do odpowiednich kanałów komunikacji (email, slack, pagerduty, itp.). Trzecim składnikiem są różnego rodzaju exportery, eksportujące metryki odpowiednich usług, np. całych hostów, mysql-a, redisa czy haproxy. Lista exporterów jest już dość duża: https://prometheus.io/docs/instrumenting/exporters/ .
To podstawowe narzędzia, które wymaga zarządzanie serwerem.
Monitoring dzielimy na 3 poziomy:
Monitoring parametrów serwera realizowany w ramach zarządzania serwerem
Pierwszy to monitoring podstawowych parametrów serwera. Wykrywa zwykle już stany podejrzane (warning) lub awaryjne (critical). Jest pierwszą i czasem ostatnią linią obrony w rękach profesjonalnego administratora. W jego skład wchodzi sprawdzanie bardzo technicznych parametrów serwera, np.:
-
zajętość dysków (check disk),
-
poprawność zamontowania dysków (check mount),
-
czas odpowiedzi na ping,
-
obecność wszystkich zdefiniowanych interfejsów sieciowych (check intefaces),
-
obciążenie serwera (check load, load per cpu),
-
działania cronów (check crons),
-
wielkość kolejki pocztowej (check mailq),
-
działanie serwera www (check http, check https),
-
działanie systemu transportu poczty (check MTA),
-
działanie baz danych (MySQL, Postgress Process, Service),
-
dostępność usługi SSH czy sFTP,
-
wykorzystanie pamięci RAM (RAM memory usage),
- i wiele innych.
Dodatkowo, pojawia się wiele specjalistycznych kontrolek, zależnie od usług serwera, np.
-
check Memcached,
-
check RAID,
-
sprawdzenie działania replikacji bazy (np. mysql replication service).
Pojawia się tu także wiele innych usług oraz napisanych przez nas indywidualnych wtyczek i checków.
Dobry system monitoringu sam potrafi wiele podpowiedzieć i skonfigurować. Tuning ustawień, ustalenie, co jest ostrzeżeniem a co alarmem to już wiedza, doświadczenie i tajniki administrowania serwerem, które wymagają obserwacji zachowania się systemu.
Zarządzanie serwerem - przeciwdziałanie problemom i awariom - monitoring z predykcją (przewidywaniem) zachowań realizowany w ramach zarządzania infrastrukturą IT
Drugi poziom to poziom przewidywania zachowania się serwera w przyszłości czyli czyste zapobieganie problemom. To zdecydowanie ważniejsza część monitoringu niż pierwsza, która zwykle zadziała, gdy już coś się podzieje albo służyć powinna sprawdzeniu usług np. po restarcie, aktualizacjach z restartami itp. W ramach Prometeusza są to przykładowo:
Alert - DiskWillFillIn4h - predykcja za pomocą aproksymacji liniowej. Alert ma w Prometheus severity jako page (najmniejszy) bo jest bardziej informacyjny i zdarzają się false-positive'y. Taki alert ostrzega nas przed tym, że jeśli zapełnianie dysku będzie postępowało tak jak teraz to za około 4h zostanie on zapełniony. Konsekwencje tego stanu zależą od wolumenu ale możemy mieć do czynienia z utratą logów, utratą danych nowo dodawanych (bezpowrotnie) lub awarią i uszkodzeniem danych systemu w bardzo poważnym stopniu (np. kiedy zapełnieniu ulegnie wolumen bazy danych).
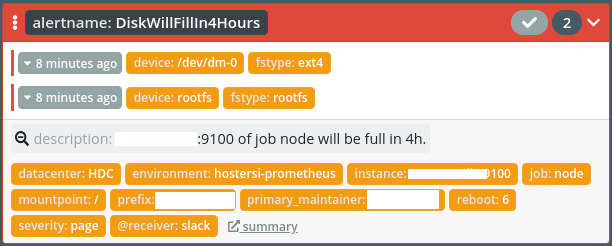
SSLCertExpiringSoon - ustawiony raz na 7 dni, żeby dać nam odpowiednią poduszkę bezpieczeństwa oraz czas na kontakt z klientem i/lub na zakup certyfikatu. Jest ostatnią deską ratunku, jeśli administracyjnie zapomnimy o nowym certyfikacie lub ulegnie awarii mechanizm LetsEncrypt. Konsekwencje braku certyfikatu są dziś katastrofalne - oznacza to niedziałanie serwisu. Jako Hostersi ratujemy czasem klienckie serwery instalacją LetsEncrypta awaryjnie. Zdarza się tak, kiedy to klient sam dostarcza certyfikaty.
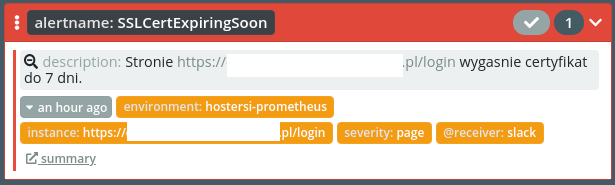
NoBackupOnHost - na zrzucie jest przykład mysql-a, ale monitorujemy również inne bazy: postgresql, mongodb. Oparty na monitoringu uruchomionych usług na hostach oraz na naszych wewnętrznych skryptach sprawdzających status backupów. To silnie customowy alert będący trzecią linią obrony i sprawdzający tych, którzy sprawdzają aktualność kopii - bo to krytyczne miejsce, które jeśli zawiedzie, możemy się długo nie dowiedzieć - póki dane nie będą potrzebne.
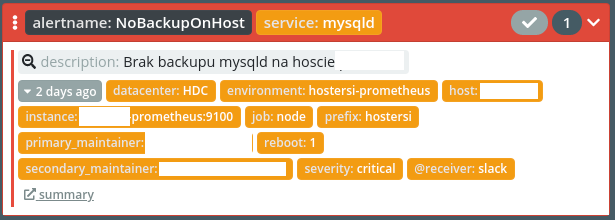
ConsistentHighLoad - alert pojawia się, gdy obciążenie na serwerze przekracza pewną wartość przez dłuższy czas (24h). Często pozwala na detekcje zawieszonych usług oraz uruchomionych niepożądanych usług typu koparki cryptowalut (bitcoin). Obciążenie na serwerach najczęściej ma rozkład normalny (większy w dzień, mniejszy w nocy), koparki powodują, że to obciążenie robi się równomierne i to alert wyłapuje.
InterfaceAt10Mbit - alert wyłapujący zdegradowaną prędkość na interfejsie. Taka sytuacja mocno wpływa na wydajność sieciową serwera. Może się to zdarzyć w czasie restartu interfejsu np. wirtualnego i jeśli dotyczy interfejsu zarządczego albo backupowego, to łatwo tego nie wykryjemy.
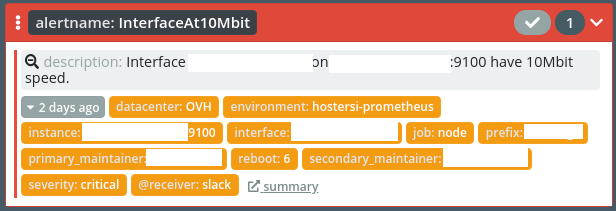
A takie typowe alerty Prometheusa to na przykład:
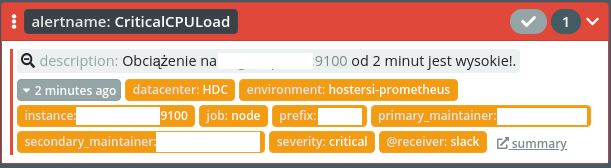
CriticalCPULoad - zwykłe obciążenie procesorów
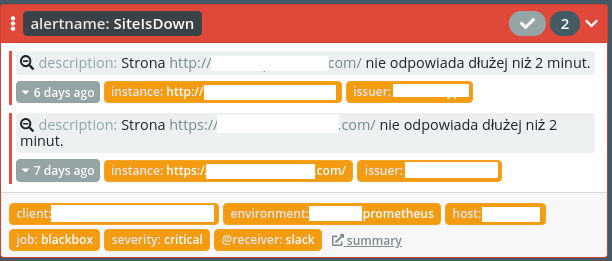
SiteIsDown - brak odpowiedzi serwera
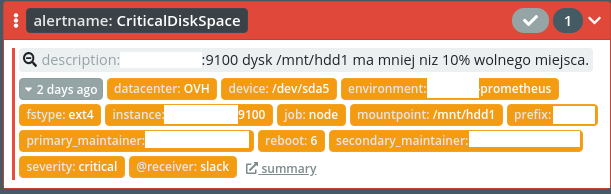
CriticalDiskSpace - kończące się miejsce na dysku
Profesjonalne administrowanie systemem wymaga jednak kroku dalej
Trzeci poziom to poziom monitoringu biznesowego. Naszego klienta, czy klienta naszego klienta, nie interesuje, że strona nie działa bo jest zajęty dysk, zwolniła bo coś się wolniej ładuje, bo robi się backup, albo dysk się zapełnia. Jego interesuje efekt końcowy - system ma działać sprawnie i wydajnie, czyli wykonywać zadania w zdefiniowanym czasie. Zdarza się też, że żaden z powyższych alertów i systemów nic nie pokazuje, a... serwis nie działa.
Tu z pomocą przychodzi trzeci poziom monitoringu - testy contentowe, czasu ładowania, czasu odpowiedzi itp. Konfigurujemy zestaw czynności, które symulują zachowanie przeciętnego użytkownika, czy też wykonują jakiś komplet czynności na stronie. Tak, jak robi to utrzymywany system i w tym samym języku. Skrypty mierzą czas i zgodność odpowiedzi z wzorcem. Na tej podstawie można zbudować wykres pokazujący zachowanie tolerowane (a może nie?) oraz ustalamy wartości metryk, które uznajemy za niepokojące lub alarmowe. W szczególności brak zgodności odpowiedzi oznacza awarię (np. Redis jako usługa działa i test czy działa zwraca true, ale ten sam Redis nie zwraca już żadnych danych).
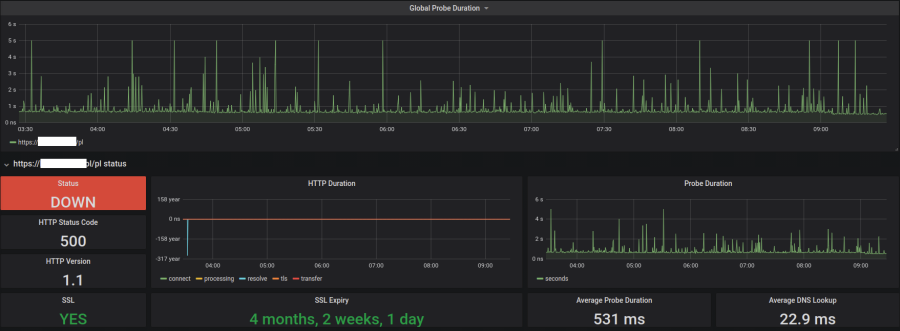
Wykresy pokazują, że czas odpowiedzi jest w miarę stały - poniżej 1 sek. Ale na wykresie widać minimalne skok w dół około 9:00-tej. Wtedy też strona, pomimo poprawnego renderowania html-a, zwraca kod 500. Posiadając też takie metryki jak wyżej, można wykrywać np. czas odpowiedzi wyższy niż 2s i szukać przyczyn skoków czasu ładowania ponad 1sekundę. Prawdopodobnie inne alerty nie towarzyszą tak krótkim pikom i tylko taki monitoring może coś wyłapać.
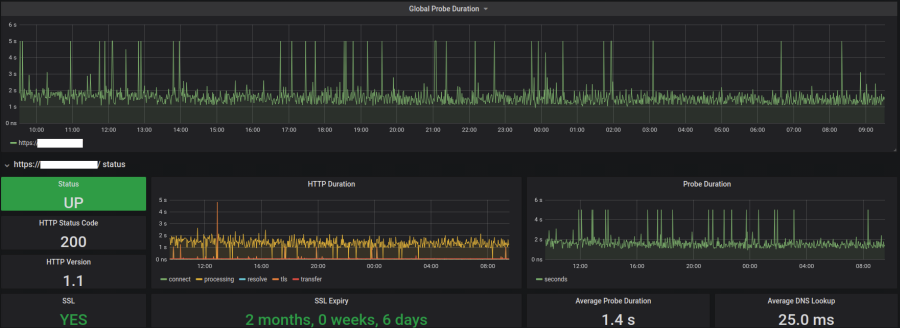
Natomiast tutaj strona aktualnie zwraca poprawny kod, ale widać na wykresie, że czas odpowiedzi jest, po pierwsze, większy (średnio 1.5s), ale również ma większy rozkład - od 1 sek do 2 sekund. I zdarzają się piki. Takie dane też są podstawą do odpowiednich alertów i "śledztwa" w poszukiwaniu przyczyn.
Podsumowanie. Zarządzanie infrastrukturą IT - monitoring
Jako Hostersi widzieliśmy już wiele, wiele się nauczyliśmy z niezliczonej ilości problemów. Wiemy co i jak monitorować i jak wykonując profesjonalne administrowanie serwerem wykryć problem, zanim wystąpi, albo wyłapać nawet najbardziej nietypowe zachowania. Takie systemy, jak Prometheus pozwalają nam, po namierzeniu jakiegoś problemu w jednym systemie, szybko skontrolować i zaaplikować odpowiednie "checki" hurtowo w całej monitorowanej infrastrukturze.
Zobacz, na czym dokładnie polega nasze Zarządzanie i administracja serwerami

Porozmawiajmy o Twoim projekcie
Opisz nam swój projekt, wyzwanie lub pytanie - odezwiemy się z konkretną odpowiedzią. Zazwyczaj odpowiadamy w ciągu jednego dnia roboczego.
