




 dla bazy danych InfluxDB w oparciu o chmurę Amazon Web Services")
Rozwiązanie High Availability (HA) dla bazy danych InfluxDB w oparciu o chmurę Amazon Web Services to ciekawa opcja dla infrastruktur, wykorzystujących Apache Kafka oraz usługę InfluxDB. W dzisiejszym wpisie podpowiadamy, jak zbudować mechanizm HA i nie płacić przy tym kroci za licencję enterprise.
Chociaż High Availability jest terminem występującym w różnych kontekstach systemów IT, wdrożenie mechanizmów HA ma za zadanie zachowanie nieprzerwanej pracy jednego, bądź wielu komponentów infrastruktury – nawet w przypadku awarii pewnej liczby elementów wchodzących w skład danego komponentu systemu IT.
Krótko o usłudze InfluxDB
InfluxDB jest najbardziej popularną oraz najszybciej rozwijającą się usługą bazodanową (TTSDB’s – Time Series Databases). Jest bazą danych, która wspiera zarówno silnik baz danych NoSQL jak i SQL. Umożliwia przechowywać różnego rodzaju dane np. metryki aplikacyjne, dane z wszelkiego rodzaju czujników czy własne niestandardowe dane. InfluxDB oferuje wersję „Open Source” bez możliwości natywnej konfiguracji High Availability oraz edycję „Enterprise”, która wspiera mechanizm High Availability. Wersja Enterprise jest bardzo kosztowna co niestety może się okazać nieopłacalnym rozwiązaniem dla małych bądź średnich infrastruktur. Podzielimy się z Wami przykładem implementacji wysokiej dostępności dla popularnej usługi bazodanowej InfluxDB w wersji Open Source przy wykorzystaniu technik DevOps
Jak to będzie działać?
Proponowane rozwiązanie wdrożenia mechanizmu High Availability w ramach usługi InfluxDB opiera się na synchronizacji danych z odrębnej usługi, która posiada wszystkie dane, jakie chcemy przechowywać w usłudze InfluxDB – w przedstawionym przeze mnie przykładzie będzie to Apache Kafka. Dzięki zastosowaniu zewnętrznego źródła danych wszystkie węzły InfluxDB będą bezstanowe – oznacza to, że w dowolnym momencie każdy z węzłów będzie mógł zostać usunięty oraz utworzony na nowo, ponieważ dane, które są wyświetlane np. w Grafanie (z InfluxDB jako źródło danych) znajdują się również w Apache Kafka. Rozwiązanie takie pozwala dodatkowo pominąć problem backupu usługi InfluxDB. Za mechanizm synchronizacji odpowiadać będzie popularna usługa Telegraf “uzbrojona” w odpowiednie wtyczki, która pobierać będzie dane oraz je synchronizować.
Kilka słów o usłudze Apache Kafka
Apache Kafka jest to rozproszony magazyn danych zoptymalizowany do pozyskiwania i przetwarzania danych strumieniowych w czasie rzeczywistym. W nawiązaniu do oficjalnej dokumentacji oferuje trzy podstawowe funkcjonalności:
- Publikowanie oraz subskrybowanie strumieni rekordów podobnie jak ma się to w systemach kolejkowania.
- Przechowywanie strumieni rekordów w sposób odporny na awarie (fault-tolerance)
- Procesowanie strumieni rekordów w czasie rzeczywistym.
Apache Kafka głównie wykorzystywany jest do budowania aplikacji opartych o procesowanie wydarzeń w czasie rzeczywistym pochodzących z wielu źródeł bądź aplikacji.
Obserwację działania Kafki można zobaczyć na poniższym diagramie, który przedstawia komunikację z klastrem:
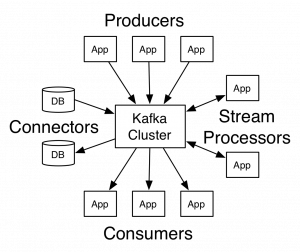
źródło: https://kafka.apache.org
Kafka oferuje nam cztery podstawowe interfejsy:
- Producent – służy do opublikowania rekordów na jeden bądź wiele “tematów” Kafki.
- Subskrybent – umożliwia aplikacji subskrybowanie jednego lub większej liczby tematów i przetwarzanie wygenerowanych dla nich rekordów.
- Pozwala aplikacji działać jako procesor strumieniowy, zużywając strumień wejściowy z jednego lub więcej tematów i wytwarzając strumień wyjściowy do jednego lub więcej tematów wyjściowych, skutecznie przekształcając strumienie wejściowe w strumienie wyjściowe.
- Pozwala budować i uruchamiać producentów lub konsumentów wielokrotnego użytku, którzy łączą tematy Kafka z istniejącymi aplikacjami lub systemami danych
Temat to nazwa kategorii lub kanału, do której publikowane są rekordy. Tematy w Kafce są zawsze subskrybentami; to znaczy że, temat może mieć zero, jednego lub wielu konsumentów, którzy subskrybują zapisane w nim dane.
High Availability(HA) dla InfluxDB przy użyciu Kafki
Rozwiązanie opiera się na prostym pomyśle – skoro InfluxDB w wersji OpenSource nie posiada możliwości klastrowania per se, dostarczamy do rozwiązania komponentu wprowadzającego taką funkcjonalność. Apache Kafka zrealizowany jest bezpośrednio z możliwościami klastrowania – służy więc natywnie takimi możliwościami i traktowany jest przez InfluxDB jako źródło danych. 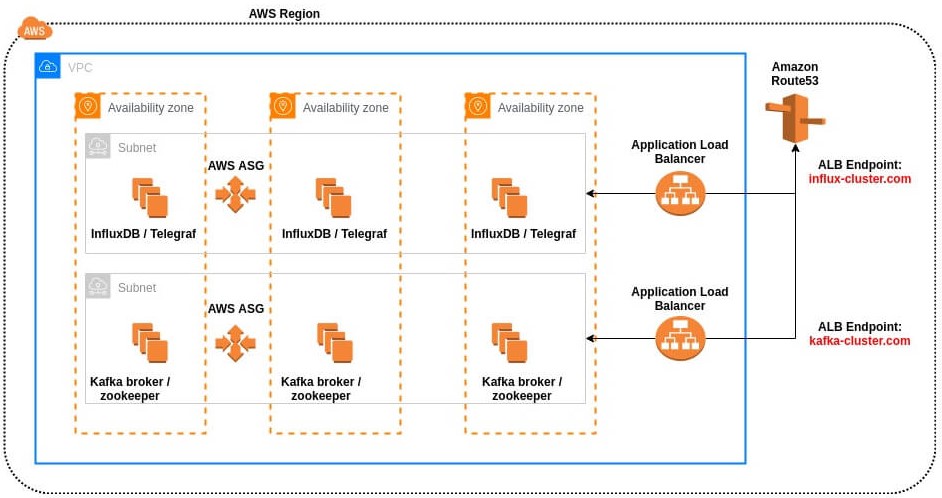
Schemat rozwiązania High Availability(HA) InfluxDB
Zastosowanie dostępnego w AWS mechanizmu grupy autoskalujacej wprowadza dodatkowo odporność na awarie (Fault Tolerance) – w przypadku awarii którejkolwiek z maszyn InfluxDB, jest ona automatycznie niszczona i uruchamiana na nowo.
Telegraf jako synchronizator
Jedną z czołowych usług w prezentowanym rozwiązaniu jest usługa Telegraf. Usługa ta, służy do zbierania bądź wysyłania różnych rodzajów danych. Usługę można implementować w postaci agenta bądź uruchomić jako mikro usługę w środowisku dockerowym, dodatkowo jest narzędziem typu “open-source”, zatem jest on całkowicie darmowy oraz bardzo rozwijanym oprogramowaniem o czym świadczy ogromna liczba wtyczek – obecnie jest ich ponad 200.Wtyczki te służą np. do integracji różnych magazynów danych – w podanym przykładzie zastosowana została integracja pomiędzy InfluxDB oraz Apache Kafka.
ELB Health check na ratunek
Warto pamiętać o tym, aby zastosować tzw. “ELB health check” w ramach load balancera, podpiętego pod instancje znajdującego się w grupie automatycznego skalowania usługi InfluxDB. Health Check w przypadku wykrycia nieprawidłowości z danym węzłem automatycznie usunie go zarówno z loadbalancer’a jak i grupy automatycznego skalowania co spowoduje zastąpienie wadliwej instancji nową instancją, która zostanie zsynchronizowana za pomocą usługi Telegraf. W celu poprawnego działania całego mechanizmu, health check powinien sprawdzać zarówno stan usługi InfluxDB jak i Telegraf.
Wady i zalety powyższego rozwiązania zostały zebrane w poniższej tabeli
| Zalety | Wady |
|---|---|
| Wysoka dostępność oraz odporność na awarię całego zestawu maszyn InfluxDB. | Konieczność zastosowania oraz utrzymywania kolejnego źródła danych, potrzebnych do synchronizacji (proponowane rozwiązanie - Apache Kafka - posiada natywnie możliwość klastrowania). |
| Brak konieczności wykonywania kopii zapasowej usługi InfluxDB. | Konieczność wykonywania kopii zapasowych w ramach użytego źródła danych. |
| Automatyczne wykrywanie oraz naprawianie w przypadku problemów z danym węzłem InfluxDB. | |
| Cały klaster dostępny jest pod jednym endpointem, który kieruje na loadbalancer. | |
| Zwiększona wydajność oraz automatyczne skalowanie klastra, z racji tego, iż zastosowany jest loadbalancer oraz grupa autoskalująca. |
Podsumowanie
W artykule przedstawiłem, jak można zrealizować wysoko dostępną usługę InfluxDB za pomocą podstawowych mechanizmów chmurowych, jakimi są LoadBalancery i grupy automatycznego skalowania.
Marcin Glazer
DevOps Engineer, Hostersi
Pytania? Skontaktuj się z nami
Zobacz również:
Wysoka dostępność serwisu. Jak ją ustalić i wyliczyć?
Skąd się bierze wysoka dostępność (HA) w chmurze?
Chmura AWS na czas sprzedaży biletów na koncert Justina Biebera

