




Dwa lata temu AWS uruchomił usługę S3 Intelligent-Tiering, która umożliwiła korzystanie z S3 bez konieczności dogłębnego zrozumienia wzorców dostępu do danych. Niedawno platforma wprowadziła dwie nowe optymalizacje dla S3 Intelligent-Tiering, które automatycznie archiwizują rzadko używane i odwiedzane obiekty. Optymalizacje te zmniejszają ilość ręcznej pracy, którą należało by wykonać, aby zarchiwizować obiekty o niesprecyzowanych wzorcach dostępu oraz te, które nie są używane miesiącami.
Czym jest S3 Intelligent-Tiering?
S3 Intelligent-Tiering to klasa pamięci masowej, która została zaprojektowana w celu optymalizacji kosztów poprzez automatyczne przenoszenie danych do najbardziej ekonomicznej warstwy dostępu bez wpływu na wydajność lub koszty operacyjne. AWS dodał klasę S3 Intelligent-Tiering do Amazon S3, aby rozwiązać problem wykorzystania odpowiedniej klasy pamięci i optymalizacji kosztów w przypadku nieregularnych schematów dostępu.
S3 Intelligent-Tiering zapewnia automatyczne oszczędności poprzez przenoszenie poszczególnych obiektów pomiędzy tierami, podczas zmian wzorców dostępów. Jest to idealna klasa pamięci masowej, gdy istnieje potrzeba zoptymalizowania kosztów dla danych, które mają nieokreślone lub nieprzewidywalne wzorce dostępu. Za niewielką miesięczną dopłatą za monitorowanie obiektów i automatyzację, S3 Intelligent-Tiering nadzoruje wzorce dostępu i automatycznie przenosi obiekty z jednej warstwy na drugą.
Co nowego od AWS?
Aby jeszcze bardziej obniżyć koszty magazynowania, wielu klientów woli archiwizować rzadko dostępne obiekty bezpośrednio w S3 Glacier lub S3 Glacier Deep Archive. Jednak wymaga to budowania złożonych systemów, które rozumieją wzorce dostępu do obiektów przez długi okres czasu i archiwizują je, gdy nie są one używane przez dłuższe okresy czasu.
AWS ogłosił dwa nowe poziomy dostępu do archiwów przeznaczone dla dostępu asynchronicznego, które są zoptymalizowane pod kątem rzadkiego dostępu po bardzo niskich kosztach: Archive Access tier oraz Deep Archive Access tier. Można wybrać jeden lub oba poziomy dostępu do archiwów oraz skonfigurować je na poziomie kontenera, prefiksu lub tagu obiektu.
Obecnie, dzięki S3 Intelligent-Tiering, można uzyskać wysoką przepustowość oraz niewielkie opóźnienie dostępu do danych, gdy są one potrzebne natychmiast, a także automatycznie zapłacić około 1 dolara za TB (terabajt) miesięcznie, gdy obiekty nie były odwiedzane przez 180 dni lub więcej. Wcześniej klienci S3 Intelligent-Tiering osiągnęli do 40% oszczędności, a teraz dzięki nowym warstwom dostępu do archiwów, mogą zmniejszyć koszty przechowywania danych nawet o 95% w przypadku rzadko używanych obiektów.
Możliwe poziomy dostępu:
- Poziomy Frequent Access i Infrequent Access: pierwszy zoptymalizowany jest pod kątem częstego dostępu, a drugi, służący głównie do obniżenia kosztów, zoptymalizowany jest pod kątem rzadkiego dostępu. Poziomy te zapewniają klientom niskie opóźnienie oraz wysoką przepustowość. Po 30 dniach na poziomie częstego dostępu (Frequent Access), obiekt, który nie był używany, zostanie przeniesiony na poziom rzadkiego dostępu (Infrequent Access). Poziom częstego dostępu jest wyceniany jak S3 Standard, a poziom rzadkiego dostępu jak S3 Standard - Infrequent Access.
- Poziom Archive Access (nowy): Ma taką samą wydajność i cenę jak pamięć masowa S3 Glacier.
- Deep Archive Access tier (nowy): Ma taką samą wydajność i cenę jak pamięć masowa S3 Glacier Deep Archive.
Jak działają nowe poziomy dostępu?
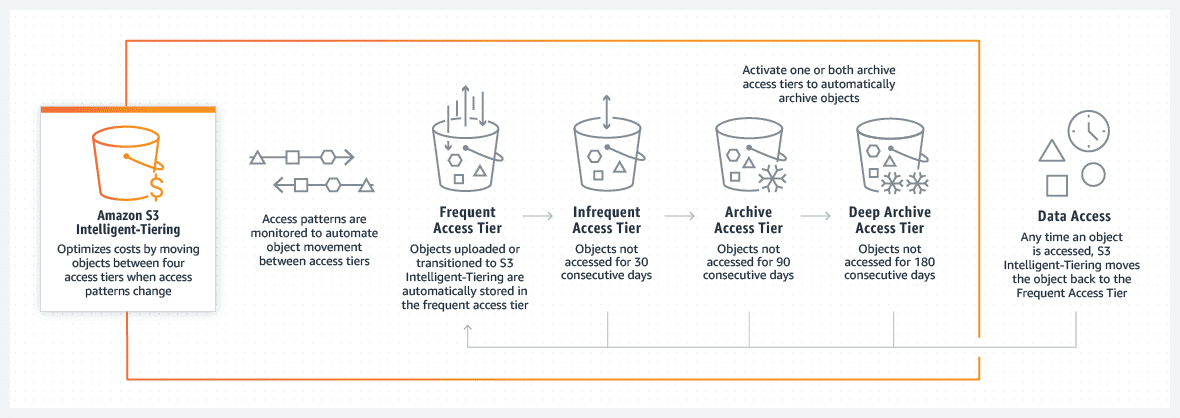
Po aktywowaniu jednego lub obu typów dostępu, mechanizm S3 Intelligent-Tiering automatycznie przenosi obiekty, które nie były używane przez ostatni 90 dni, na warstwę dostępu Archive Access, a po 180 dniach bez użycia, obiekty zostaną przeniesione do warstwy Deep Archive Access. W każdej chwili, gdy obiekt znajdujący się na jednym z poziomów zostanie przywrócony, w ciągu kilku godzin zostanie on przeniesiony na poziom Frequent Access, a wtedy będzie gotowy do pobrania.
Obiekty znajdujące się na poziomie Archive Access są odzyskiwane w ciągu 3-5 godzin, a jeśli znajdują się na poziomie Deep Archive Access w ciągu 12 godzin. Jeżeli jakiś obiekt, na którymkolwiek z tierów, wymaga szybszego dostępu, jest to możliwe za dodatkową opłatą.
Jak rozpocząć przygodę z nowymi warstwami dostępu Intelligent-Tiering Archive?
Konfiguracja warstw Intelligent-Tiering jest zdefiniowana na poziomie bucketu. Najpierw, we właściwościach kontenera, należy stworzyć nową konfigurację dla Intelligent-Tiering Archive. Można zdefiniować jedną lub więcej reguł konfiguracji dla archiwum Intelligent-Tiering.
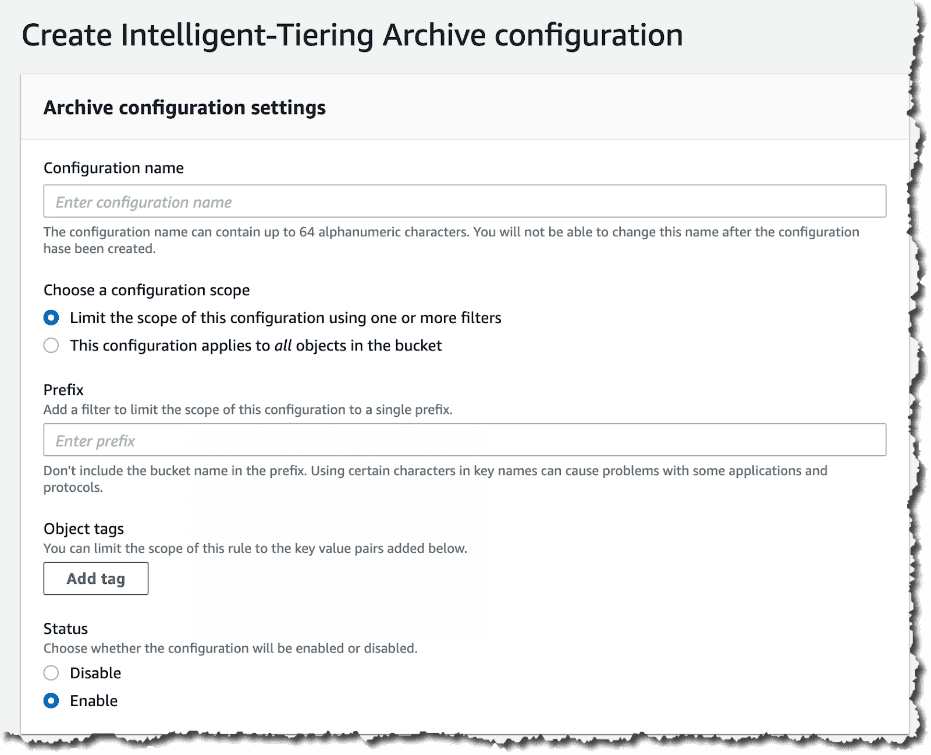
Na stronie ustawień konfiguracji archiwum można wybrać zastosowanie konfiguracji do wszystkich obiektów w kontenerze, które korzystają z klasy Intelligent-Tiering S3 lub ograniczyć zakres tej reguły konfiguracji poprzez zdefiniowanie filtrów. Dostępne są dwie opcje definiowania filtrów: prefiks obiektu lub tagi obiektów.
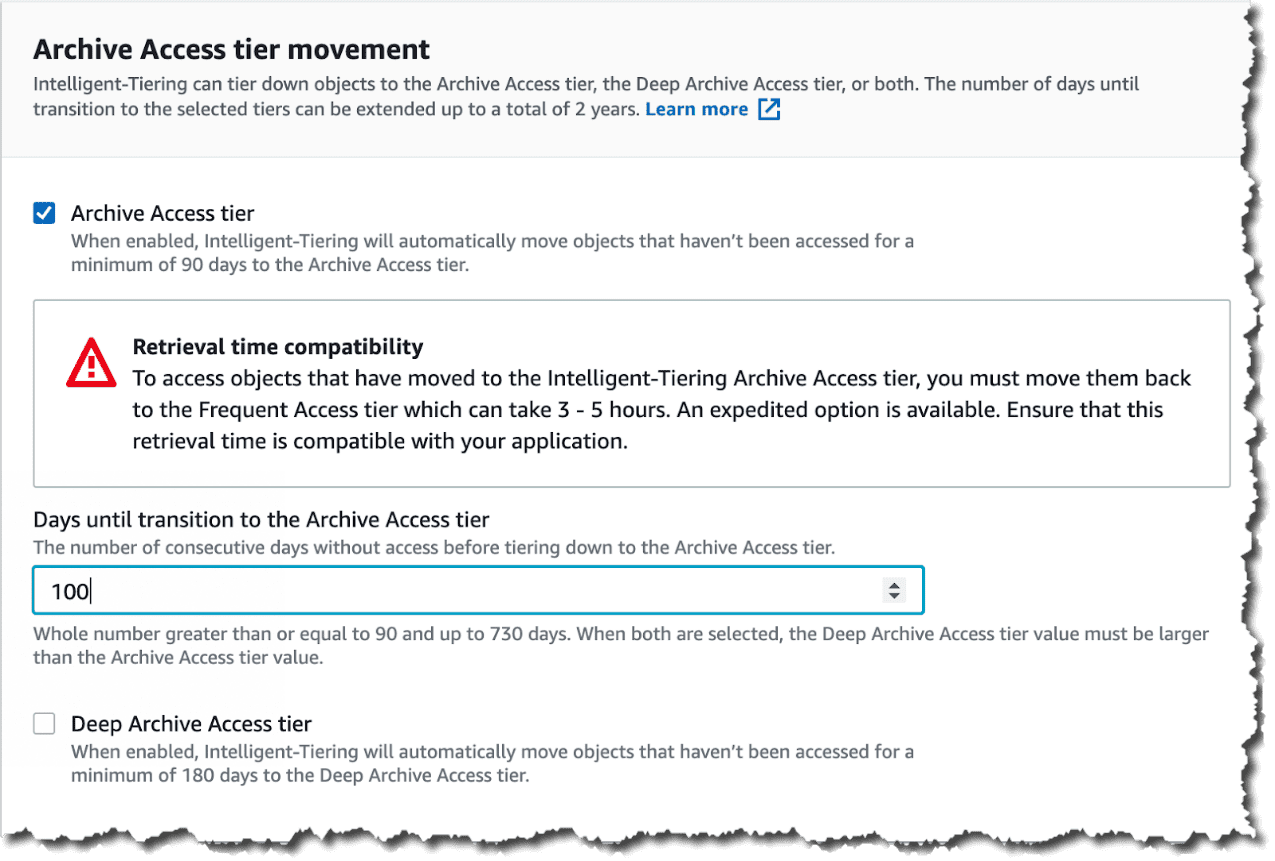
Po ustaleniu, których obiektów w kontenerze ma dotyczyć reguła, należy włączyć jeden lub obydwa poziomy dostępu. Po włączeniu jednego z nich można określić, w ciągu ilu dni obiekt ma przejść na ten poziom - dla Archive Access liczba ta musi być równa lub większa niż 90, a dla Deep Archive Access równa lub większa niż 180 dni.
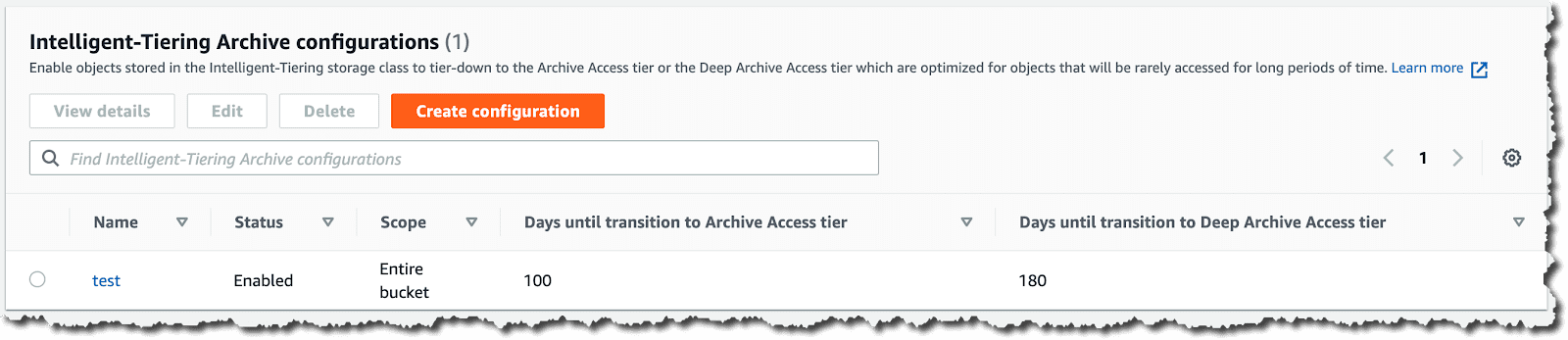
Po zakończeniu tworzenia konfiguracji, można zobaczyć wszystkie reguły we właściwościach kontenera w Intelligent-Tiering archive configurations i w każdej chwili je edytować.
Po zastosowaniu konfiguracji, gdy nowy obiekt, który odpowiada zdefiniowanym w regułach filtrom, zostanie wysłany do S3 oraz zostanie wybrana klasa pamięci Intelligent-Tiering, obiekt ten (jeśli nie jest używany) przejdzie, w miarę upływu czasu, przez wszystkie skonfigurowane poziomy dostępu.
Aby uzyskać więcej informacji na temat optymalizacji kosztów z S3 Intelligent-Tiering Archive Access Tiers, warto obejrzeć film
Kilka ostatnich rzeczy, o których należy pamiętać:
- Rozmiar obiektu: Można używać Intelligent-Tiering dla obiektów o dowolnym rozmiarze, jednak obiekty mniejsze niż 128KB będą utrzymywane na liście Frequent Access. Dla każdego obiektu zarchiwizowanego na poziomie dostępu Archive Access lub Deep Archive Access, S3 używa 8 KB pamięci dla nazwy obiektu i innych metadanych (rozliczanych według standardowych stawek przechowywania S3) oraz 32 KB pamięci masowej dla indeksów i związanych z nimi metadanych (rozliczanych według stawek przechowywania S3 Glacier i S3 Glacier Deep Archive). Pozwala to na uzyskanie w czasie rzeczywistym listy wszystkich obiektów S3 lub raportu S3 Inventory.
- Żywotność obiektu: Intelligent-Tiering jest odpowiedni dla obiektów o żywotności dłuższej niż 30 dni, a wszystkie obiekty, które korzystają z tej klasy pamięci, będą rozliczane przez co najmniej 30 dni.
- Trwałość i dostępność: S3 Intelligent-Tiering został zaprojektowany z myślą o 99,9% dostępności i 99,999999999% trwałości.
- Wycena: Opłata liczona jest za miesięczne przechowywanie, żadania i przesyłanie danych. Korzystając z Intelligent-Tiering płaci się niewielką miesięczną opłatę za monitoring i automatyzację. W S3 Intelligent-Tiering nie ma opłat za pobieranie danych i za przenoszenie danych pomiędzy warstwami.
Obiekty na poziomie Frequent Access są rozliczane według tej samej stawki co S3 Standard, obiekty przechowywane na poziomie Infrequent Access są rozliczane według tej samej stawki co S3 Standard Infrequent Access, obiekty przechowywane na poziomie archiwum Archive Access są rozliczane według tej samej stawki co S3 Glacier, a obiekty przechowywane na poziomie Deep Archive są rozliczane według tej samej stawki co S3 Deep Glacier. - Dostęp do API i CLI: Można używać Intelligent-Tiering z S3 CLI i S3 APIs z klasą pamięci masowej INTELLIGENT_TIERING. Można również skonfigurować archiwum Intelligent-Tiering za pomocą interfejsów API dla określonego kontenera.
- Obsługa funkcji: S3 Intelligent-Tiering obsługuje takie funkcje jak S3 Inventory do raportowania poziomu dostępu obiektów oraz S3 Replication do replikacji danych do dowolnego Regionu AWS.
Źródło: AWS
PYTANIA? SKONTAKTUJ SIĘ Z NAMI
