Obsługa środowiska Docker. Wprowadzenie #1

Obsługa środowiska Docker to umiejętność, która znacznie ułatwia pracę DevOpsów. Docker to popularna platforma dla programistów i administratorów, przeznaczona do tworzenia, wydawania oraz uruchamiana aplikacji w oparciu o tzw. kontenery. Niektórzy obwieszczają Dockera przyszłością wirtualizacji, a część programistów i adminów już teraz nie może się bez niego obejść. Czym właściwie jest Docker i co powinniśmy o nim wiedzieć? Zapraszamy do lektury pierwszego z trzech wpisów, wyjaśniających meandry tej technologii.
Obsługa środowiska Docker – wprowadzenie
Błyskawicznie postępujący rozwój technologii powoduje, że coraz bardziej jesteśmy świadomi wszelkich zagrożeń, które ze sobą niesie. Zagrożenia bezpieczeństwa występują już praktycznie na każdym poziomie, począwszy od infrastruktury fizycznej, aż po samą logikę aplikacyjną. Między innymi właśnie kwestie bezpieczeństwa spowodowały odejście od dotychczasowego modelu aplikacji monolitycznej na rzecz systemów rozproszonych.
Początkowo separację zapewniały dedykowane maszyny fizyczne, osobne dla każdej aplikacji. Posiadały niezależne komponenty, gwarantujące brak wpływu jednej aplikacji na drugą. Rozwiązanie to jednak było bardzo kosztowne, a także, w znacznym stopniu prowadziło do marnowania zasobów obliczeniowych.
Z czasem standardem stały się dedykowane serwery wirtualne ? VM/VPS. Pozwalało to uruchomienie kilku niezależnych maszyn (wirtualnych) w ramach jednej maszyny fizycznej. Gwarantowały one ten sam poziom izolacji, jaki dawały niezależne maszyny fizyczne, jednak znacznie mniejszym kosztem. Dodatkowo każda z maszyn wirtualnych (VM) miała przydzielone zasoby sprzętowe zgodne z faktycznymi potrzebami, dzięki czemu pozostałe mogły zostać przeznaczone na uruchomienie kolejnej VM.
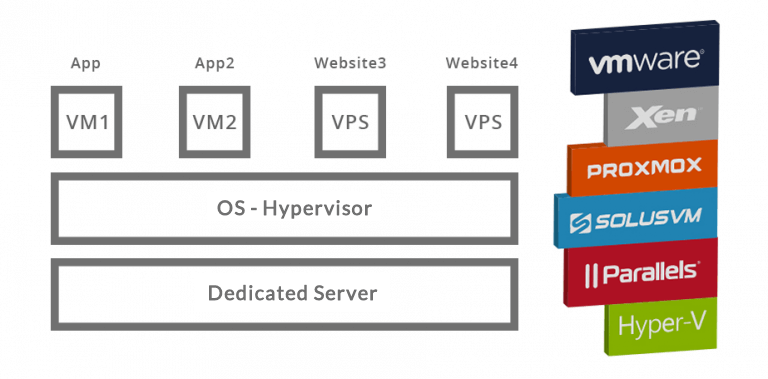
Schemat serwera zwirtualizowanego
Rozwój aplikacji w podejściu scentralizowanym spowodował jednak, że wraz z upływem czasu, w wielu systemach można było zaobserwować swego rodzaju „nawarstwianie” funkcjonalności. Efektem tego był czasochłonny proces analizowania i wdrażania każdej zmiany, tak aby nie wpłynęła ona na pozostałą część systemu. Skalowalność takiego systemu była utrudniona i polegała na jego powielaniu. Wymusiło to zmianę podejścia – podział aplikacji na małe elementy, możliwie niezależne, łatwo skalowalne – wdrożenie mikroserwisów/mikrousług.
Systemy w architekturze zorientowanej na mikrousługi tworzone są w oparciu o kontenery. Pozwalają one na rozproszenie funkcjonalności, dzięki czemu zyskujemy wysoką elastyczność oraz skalowalność rozwiązania przy jednoczesnym zachowaniu pełnej izolacji tych elementów. Tworzenie kontenerów oraz zarządzanie nimi może odbywać się poprzez jedno z kilku narzędzi, z których najpopularniejszym jest Docker.
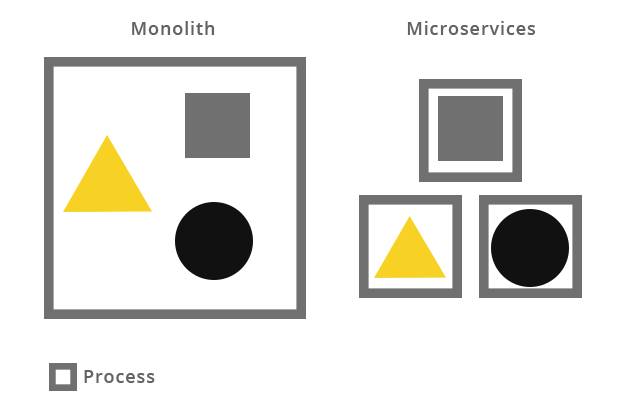
Struktura mikroserwisów/mikrousług (centralny punkt i reszta elementów)
Docker jest platformą bazującą na metodzie wirtualizacji LXC. Pozwala ona na odizolowanie aplikacji od systemu operacyjnego, a także przydział konkretnych zasobów – CPU, RAM czy HDD. Te z kolei są realizowane poprzez grupy kontrolne i przestrzenie nazw, które to pozwalają na zarządzanie dostępem do zasobów (np. sieci) przez poszczególne procesy. Platforma składa się z dwóch elementów: Docker Engine oraz repozytorium obrazów (Registry).
Obsługa środowiska Docker. Podstawowe elementy
Docker Engine to główna składowa – aplikacja typu klient-serwer, złożona z trzech elementów: klienta (CLI), serwera (daemon-a) oraz REST API.
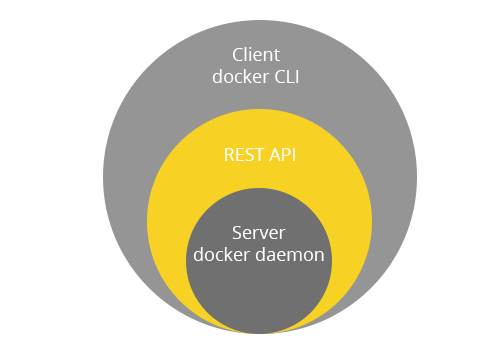
Struktura Docker Engine
Daemon Docker-a jest centralnym miejscem, z którego następuje zarządzanie kontenerami jak i obrazami. Dotyczy to zarówno ich pobierania, budowy czy uruchamiania. Polecenia do wykonywania tych czynności są przesyłane przez klienta z wykorzystaniem Docker REST API. Same obrazy są natomiast przechowywane w repozytorium obrazów, czy to publicznym czy prywatnym – np. Docker Hub. W tym miejscu należy zaznaczyć, że poza wieloma oficjalnymi obrazami udostępniane są również nieoficjalne ? budowane przez społeczność Docker-a.
W odróżnieniu od maszyn wirtualnych, kontenery wymagają dużo mniejszych zasobów do samego uruchomienia, a i sam czas ich uruchomienia jest znacząco niższy. Zostało to jednak uzyskane kosztem zmniejszenia izolacji pomiędzy kontenerem, a samym systemem operacyjnym ? poprzez współdzielenie jądra systemu.
Obrazy są tak naprawdę szablonami w trybie read-only, z których kontenery są uruchamiane. Składają się one z wielu warstw (layer-ów), które, dzięki zastosowaniu ujednoliconego systemu plików (UFS), Docker łączy w jeden konkretny obraz. Podstawą każdego jest obraz bazowy, np. Ubuntu, na który nakładane są kolejne warstwy. Każda kolejna czynność (instrukcja) wykonywana na obrazie bazowym tworzy kolejną warstwę, np. wykonanie komendy czy utworzenie pliku/katalogu. Komplet instrukcji tworzących obraz jest przechowywany w pliku Dockerfile. Podczas żądania pobrania obrazu przez klienta, plik ten jest przetwarzany, czego wynikiem jest finalny obraz.
Poprzez zastosowanie warstw uzyskano bardzo niskie zużycie przestrzeni dyskowej, ponieważ podczas zmiany obrazu czy jego aktualizacji, budowana jest nowa warstwa, która zastępuje poprzednią (aktualizowaną). Pozostałe warstwy pozostają nienaruszone. Oznacza to, iż możliwe jest współdzielenie warstw tylko do odczytu pomiędzy kontenerami, czego efektem jest dużo niższe zużycie przestrzeni dyskowej, w porównaniu do standardowych VM.
Registry, czyli repozytorium obrazów, jest faktycznym miejscem przechowywania obrazów. Może być publiczne bądź prywatne, lokalne bądź zdalne. Najpopularniejszym repozytorium jest Docker Hub, który oferuje wiele dodatkowych funkcjonalności, np. możliwość utworzenia repozytorium prywatnego. Oczywiście istnieją inne platformy, które pozwalają na przechowywanie swoich obrazów, jak np. Quay.io, ale możliwe jest także utworzenie własnej biblioteki ? czy to lokalnie na komputerze, na którym został zainstalowany Docker czy zdalnie, na jednej z innych maszyn, którymi zarządzamy.
Wspomniany wielokrotnie kontener to efekt ujednolicenia warstw tylko do odczytu oraz pojedynczej warstwy do odczytu i zapisu, dzięki której możliwe jest funkcjonowanie wymaganych zadań. Kontener wykonuje określone wcześniej zadanie, najczęściej jedno. Zawiera system operacyjny, pliki użytkownika, a także tzw. metadane, dodawane automatycznie podczas tworzenia bądź startu kontenera.
Kontener określany jest również jako ‚środowisko wykonywalne Docker-a’. Może przyjmować jeden z pięciu stanów:
- created ? utworzony, gotowy do uruchomienia,
- up – działający, wykonujący zadanie,
- exited- wyłączony, w trybie bezczynności po zakończeniu zadania,
- paused ? wstrzymany,
- restarting ? w trakcie ponownego uruchamiania.
Czas działania kontenera jest zależny od zadania, które wykonuje. Samo uruchomienie składa się z siedmiu kroków:
- Pobrania wybranego obrazu, pod warunkiem, że nie stał już pobrany wcześniej.
- Utworzenia kontenera.
- Załadowania systemu plików i utworzenia warstwy do odczytu i zapisu.
- Zainicjowania sieci bądź mostka sieciowego.
- Konfiguracji sieci (adresu IP).
- Uruchomienia zadania.
- Przechwytywania wyjścia – prowadzenia dziennika zdarzeń.
Możliwe jest łączenie (linkowanie) kontenerów, przez co zyskują one bezpośrednie połączenie ze sobą. Same zadania wykonywane przez kontener są tak samo wydajne, jakby były uruchamianie bezpośrednio w systemie gospodarza.
Obsługa środowiska Docker. Podsumowanie
Przedstawione wyżej informacje pozwalają zaznajomić się z budową oraz sposobem funkcjonowania Docker-a. Mimo że są to informacje o charakterze wyłączenie teoretycznym, są one niezbędne, aby prawidłowo budować i pracować w tym ekosystemie.
W kolejnym wpisie przedstawimy podstawowe działania na kontenerach oraz komendy przydatne podczas codziennej pracy. Omówimy m.in. tematy dotyczące uruchomienia kontenera, budowania własnego obrazu czy obsługi repozytorium. Jako Hostersi, chętnie pomożemy również przy projektach, wymagających użycia Dockera. Zarządzając serwerami, zwłaszcza w środowiskach chmurowych, nasi administratorzy znają tą technologię od podszewki.
Zobacz również:
Usługi wsparcia IT ? obsługa serwerów i pomoc w razie awarii 24h na dobę
Infrastruktura serwerowa bez tajemnic. Serwer dedykowany, VPS, czy chmura?
Skąd się bierze wysoka dostępność (HA) w chmurze?

44-200 Rybnik
Poland
REGON: 240692928
KRS: 275333






